データ利活用の巧拙が、企業の競争力を大きく左右することに異論を挟む余地はない。ここに力を注ぐ企業は、既にさまざまな取り組みを進めてきているが、昨今はAIを筆頭とするテクノロジの進化が目覚ましく、さらなる可能性をもたらしているのがホットトピックだ。市場の動きを概観しつつ、真のデータドリブン企業に変容するためのポイントを識者に聞く。
これまでの豊富な実績と知見を活かし、企業に対してデータ利活用の高度化を支援する先駆の一社がNTTデータだ。その中核を担うテクノロジーコンサルティング事業本部は、最先端のテクノロジを業務に適用して顧客のデジタルトランスフォーメーション(DX)を具現化することに軸足を置く。中でも、Data & Intelligence事業部は、BI(ビジネスインテリジェンス)による可視化のみならず、AI(人工知能)による予測/判定などを組み合わせて、インサイトをビジネス価値へと結びつけることにフォーカスしている精鋭組織だ。
その前線に立つ人材は現在の国内市場の状況をどのように見ているのだろうか。データマネジメント統括部でソリューション担当を務める齋藤祐希氏は次のように話す。「意欲的な大企業を中心に、DWH(データウェアハウス)やデータレイクにデータを集約してBIで気づきを得るというフェーズまでは到達しています。単に環境を整えるだけでなく、データ活用組織の立ち上げや、全社データガバナンス・マネジメントに関する相談も寄せられるようになってきました」。
 NTTデータ テクノロジーコンサルティング事業本部 Data & Intelligence事業部 データマネジメント統括部 ソリューション担当 テクニカル・グレード(シニアデータエンジニア) 齋藤祐希氏
NTTデータ テクノロジーコンサルティング事業本部 Data & Intelligence事業部 データマネジメント統括部 ソリューション担当 テクニカル・グレード(シニアデータエンジニア) 齋藤祐希氏BIを中心に活況であることが伺えるが、この域に甘んじてもいられない。齋藤氏は、さらに高度化していくにはML(機械学習)をはじめとするAIの活用が不可避であり果敢にチャレンジすることの必要性を説く。「『データを可視化し人間が判断する』段階から『データからAIを作り、AIが判断し、人間がチェックだけをする』段階、あるいは『人間ができない判断をAIが行う』段階へレベルアップしていくことが、スピード経営や顧客満足度向上につながります」(齋藤氏)。
競争が激化する金融業界ではAI活用が始まる
例えば保険業界における不正検知。保険金の支払い申請のうち、不正なものが1%あるとしよう。従来的アプローチで人の判断に重きをおいた検知なら、業務の速度と品質を上げるのには必然的に限界がある。残り99%が待たされる構図は変わらない。AIで自動判定して人が最終チェックすることを実現すれば、全体としての保険金支払いサイクルが早まり、顧客からも支持されるし他社との差異化も図れることになる。市場競争の激しい金融業界では実際にアクションが始まっているという。
他の業界でもAI活用に触手を伸ばす動きはある。もっとも、PoCは単発で実施することはあっても、それを商用システム化し、ビジネス効果につなげられているケースはまだ少ないようだ。さらに、PoC〜システム化〜ビジネス活用のサイクルを恒常的かつ効果的に回す「MLOps」まで取り組めている事例はさらに少数派だ。
この背景には何があるのか。齋藤氏は、「これまで整えてきたDWH+BIのデータ基盤に加えて、AIを開発してビジネスに適用するデータ基盤が必要となります。多くの方は従来の延長ぐらいの差と捉えていますが、実際には大きなギャップがあり、この点の認知がまだしっかりとされていないのではないでしょうか」と指摘する。
では、今後を見据えたAI活用を前提としたデータ基盤とはいかなるものなのだろうか──。
直面する課題を一掃する「レイクハウス」の新機軸
データの利活用、さらにはAIの利活用。一連の成熟度や競合に対する優位性は幾つかのステップとして捉えることができる(図1)。多面的な分析や探索的な解析などがBIによって実現されてきたが、誤解を恐れずに言えば、それは過去に何が起きたかを深堀りをしていたわけだ。我々がこれからAIの恩恵を受けようとしているのは、何が起きそうかという未来の領域。予測モデルの確立や意思決定のリコメンド、さらにはアクションの自動化といったものだ。そこにはAIを前提としたデータ基盤が必要であり、従来のDWH+BIでカバーしようとするのは、やはり無理がある。
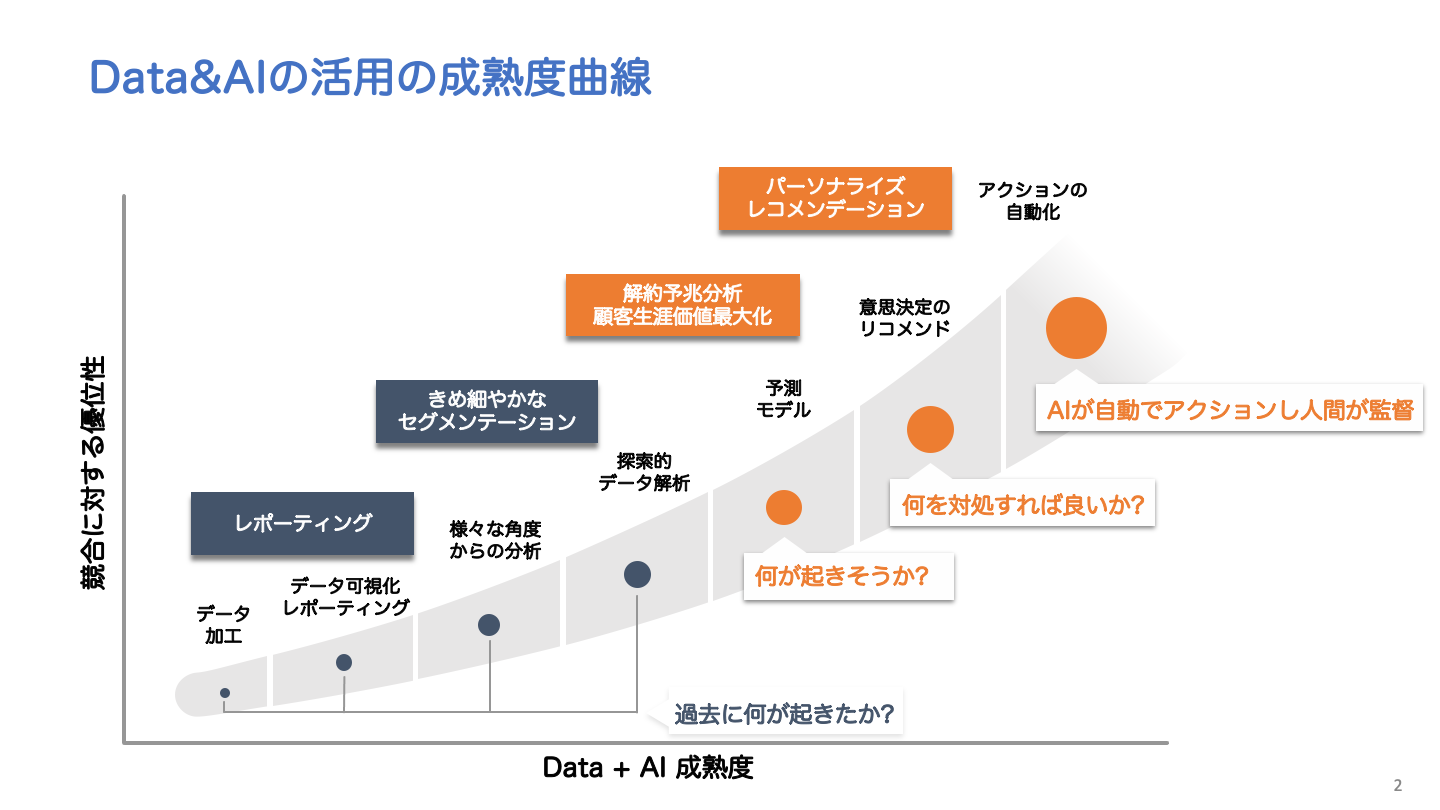 図1 データやAIを活用していく上での成熟度
図1 データやAIを活用していく上での成熟度拡大画像表示
そこで出てきた一つのアイデアはAI用途にデータレイクを別途用意し、DWHと併用しようというものだ。しかし、ここでもデータの個別分散やコスト増といった問題に直面する。「通常規模とビッグデータ、構造化データと非構造化データ、バッチ処理とリアルタイム処理、BIとAI…ユースケースごとに基盤やツールを用意するのは、部分最適が進むだけで、データも知見も分散する一方です。スピードは上がらず、コストばかりが膨れ上がってしまいます」と齋藤氏は指摘する。
この状況に一石を投じるのが「レイクハウス」という考え方だ。データレイクの強み(幅広いデータ種別に対応、幅広い言語に対応、高い拡張性)を維持しつつ、データウェアハウスの強み(高い信頼性、高い性能)を提供する。つまりは、両者の良いとこ取りをした仕組みだ。データ形式などが異なることで保存先が分散している「データのサイロ化」や、データエンジニアリングやデータサイエンス、BIなど、業務ごとに扱う手法が異なる「プロセスのサイロ化」を解消する。
レイクハウスを具現化するものとして、昨今にわかに期待と注目を集めているのが米Databricks社のレイクハウス・プラットフォームだ(以下、便宜的にデータブリックスと呼ぶ)。NTTデータも2021年5月にデータブリックス・ジャパンとのパートナーシップ契約締結をアナウンス。両社は「データとAIの民主化」を市場に訴求し、NTTデータのデータ資産を分析・活用するための環境をオールインワンで提供するソリューション「Trusted Data Foundation®」にデータブリックスを組み込んで展開するといった活動を強化する(図2)。
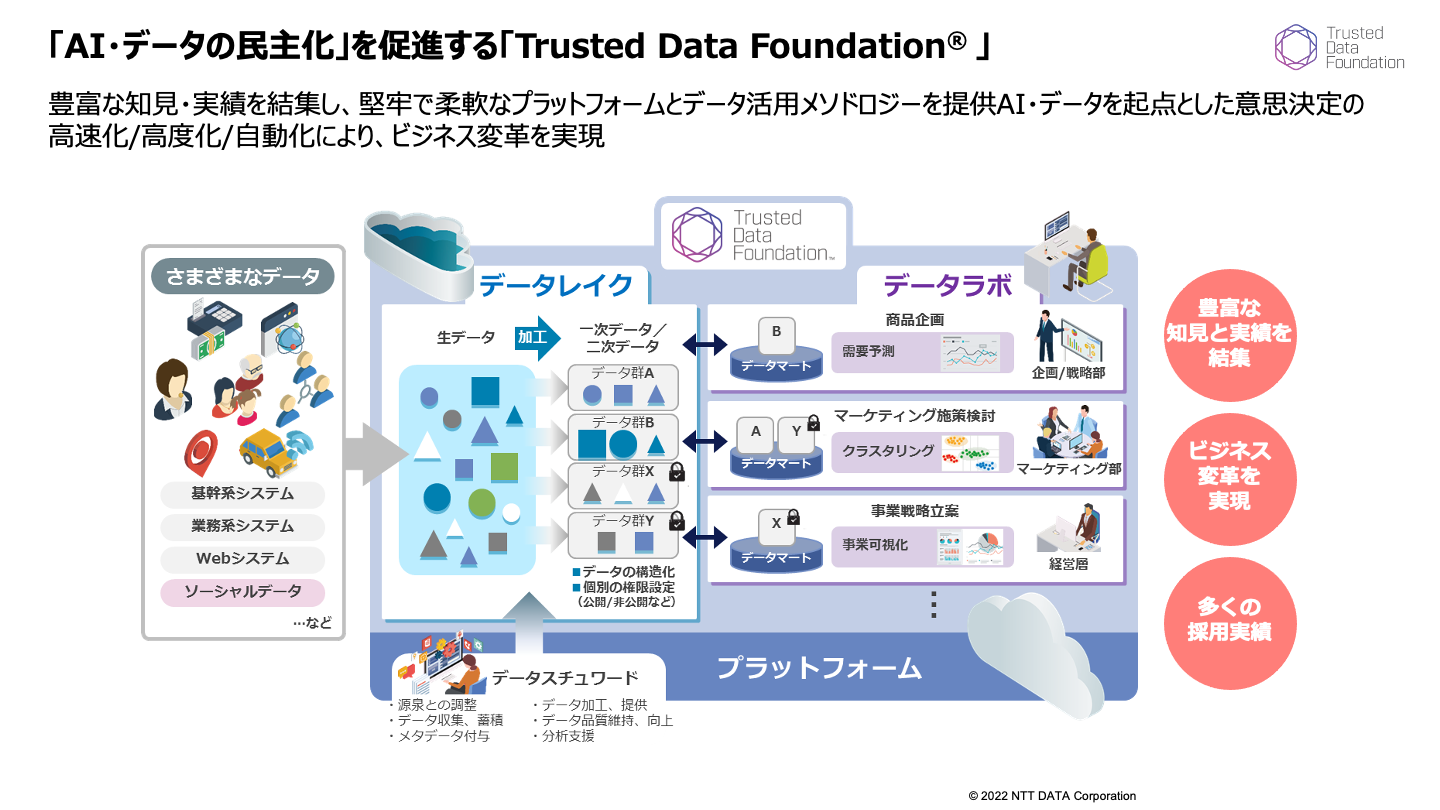 図2 「AI・データの民主化」を促進する「Trusted Data Foundation® 」
図2 「AI・データの民主化」を促進する「Trusted Data Foundation® 」拡大画像表示
オールインワン型のデータブリックスに期待と注目が集まる
データブリックスは、構造化データと非構造化データの双方をストアでき、併せてSQL分析やデータサイエンス、機械学習などの多種多様な機能をSaaSでユーザーのペルソナに合わせた使いやすいUIで実現できる点に大きな特徴がある(図3)。プラットフォーム自体はオープンかつマルチクラウド対応であり、特定のクラウドベンダーに依存することなく使える安心感も伴う。データとAIのポテンシャルを最大限に引き出すことができるわけだ。
 図3 データブリックスが提供する「レイクハウス」プラットフォームの概要
図3 データブリックスが提供する「レイクハウス」プラットフォームの概要拡大画像表示
そのアドバンテージについて齋藤氏は、「単一のデータストアで各種機能を実行できるオールインワン型のソリューションであり、常に最新で綺麗なデータを使えることと、幅広いユースケースに使えることが際立っています。これまでBIをやってきた企業が簡単にAIに手を伸ばせますし、逆にAIを活用している中で出てきたデータをBIで可視化することも容易です。AIとBIを循環させながら一緒に使えることには大きな可能性を感じます」と話す。
例えば同氏は、AmazonのApache Hive on EMRやAthenaを配したDWHベースのデータ基盤に、AIやMLの機能としてJupyter Notebookを用意するアプローチで臨んだことがある。このケースでは、SQLで直接的に機械学習ができないという事情があり、DWH上から数百GBに及ぶ大量のデータをローカルサーバーにダウンロードし、さらにそこでPythonによる前処理(特徴量エンジニアリング)や学習処理を実行することになった。リソースの枯渇や分析の遅延、サーバー費用増加やガバナンス不徹底といった問題が顕在化して、結果的にはAI開発がスムーズにいかなかったという。
「オールインワン型のデータブリックスであれば、このような問題を回避することができます。複数のユースケースに対応したシステムを、スモールスタートで始められるというのは大きなメリット。データ基盤の構築や分析の準備にいたずらに時間をかけることなく、コアとなる分析そのものに集中できる価値は絶大です。従量課金によってコスト最適化が可能なことも見逃せません」(齋藤氏)。
スモールスタートできることの価値を享受する
小さく始めて実績を積み上げていく姿勢は極めて重要だ。世の中を見渡すと、「AI活用」というスローガンが独り歩きし、重厚長大なシステムの構築やルールの整備に多大な時間やコストを費やして迷走している例が少なくないからだ。まずは、特定のシーンで成果を得ることを起点としなければならない。
この点において、データブリックスには「ソリューションアクセラレータ」があるのが心強い。これは、さまざまな業界・業種に共通の主要なユースケースに対応する、フル機能のNotebookやベストプラクティスを含む目的に特化したガイドだ。発案からPoCまでを2週間以内に完了できるよう設計されたソリューションアクセラレータを使用することで、当該の目的を達するための設計、開発、テストにかかる時間を大幅に短縮する効果を見込める。
コーヒーショップの需要予測の精緻化に挑むスターバックス、農業機械/建設機械のIoTデータ活用を本格化させている米Deere & Company、動画配信のレコメンデーションで実績のある米Netflix、創薬における画像などの非構造化データ活用に積極的な英AstraZeneca、などグローバルの事例は枚挙に暇がない。こうした先駆者による取り組みのエッセンスが、ソリューションアクセラレータにも凝縮されている。
AIとBIを循環させつつユーザーの変革を後押し
レイクハウスの考え方がさらに浸透しビジネス上の成果として結実していくためには、専門家だけではなく、実務担当者の一人ひとりがデータに興味を持って行動に移すことも欠かせないだろう。「データから価値を最大限に引き出すことがゴールであり、データのことを一番知っている現場のユーザーが最も活躍の機会があるはずです。そのためにも、AI+BIを簡単に実現できなければなりません」(齋藤氏)。
その観点において、現在のデータブリックスには改善すべき点があると齋藤氏は指摘する。「データ活用のインタフェースはデータサイエンティストのような専門家向けであり、PythonやSQLを書けることが前提になっています。これはデータブリックスだけでなく業界全体の課題ともなりますが、データとAIを民主化していくには、直感的なGUIで誰でも簡単にデータを扱えるようにしていくのが今後の方向性でしょう」。

絶賛するだけでなく、時に厳しい目も向けるのはデータブリックスに大きなポテンシャルを感じているからにほからならない。「当社が各種のオープンソースやクラウド基盤を活用して、5年をかけて設計し試行錯誤してきたことが、データブリックスという1つのプラットフォームで実現できるのは心からすごいと思っています」と話す齋藤氏は次のように締めくくった。
「実はデータブリックスは、Apache Sparkの生みの親が2013年に設立した会社。NTTデータはSparkのコミッタであり、Sparkと言えばNTTデータという自負があります。同様に、データブリックスならNTTデータと言われるところまで持っていきたいですね。その足がかりとして社内でデータブリックスを推進するCoE(センターオブエクセレンス)を設立しました。今は6名体制ですが、さらに増強していきます。データ×AIの領域で確実な一歩を踏み出したいとのニーズがあれば、是非、当社にお声がけください」。
●お問い合わせ先

株式会社NTTデータ
データブリックス製品関連: https://enterprise-aiiot.nttdata.com/service/databricks
Trusted Data Foundation® : https://enterprise-aiiot.nttdata.com/service/tdf
メール:databricks_contact@kits.nttdata.co.jp

データブリックス・ジャパン株式会社




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
