米Amazon Web Services(AWS)の最大規模リージョンの1つ「US-EAST-1」(米国東部・バージニア北部)において、2025年10月19日(PDT:太平洋夏時間)夜から20日午後にかけて、長時間にわたる大規模なネットワーク障害が発生した。この障害は単一の障害ではなく、複数の問題が連鎖的に発生したことで影響が広範囲に及び、サービスの復旧までに約15時間を要する事態となった。同社はAWSサービス群の状況を知らせる「AWS Health Dashboard」を通じて経過を報告している。
米Amazon Web Services(AWS)によると、今回の大規模なネットワーク障害の発端は2025年10月19日の午後11時49分(PDT:太平洋夏時間、以下同。日本時間では10月20日15時49分)頃、同社の最大規模リージョンの1つ「US-EAST-1」(米国東部・バージニア北部)において発生した。
「AWS Health Dashboard」(画面1)の最新報告(10月20日午後3時53分=日本時間10月21日午前7時53分)によれば、AWSのデータベースサービス「DynamoDB」のリージョンエンドポイントにおいて、サービス名から実際のサーバーのIPアドレスを特定するDNSの解決に問題が生じたという。この問題によって多数のAWSサービスでエラー率の上昇とレイテンシーが発生。また、ID管理やDynamoDBグローバルテーブルなど、US-EAST-1のDynamoDBに依存する他のサービスも即座に影響を受けた。
AWSは20日午前0時26分にこのDNS問題を特定し、午前2時24分までに解決した。しかし、今度は仮想サーバーサービス「Amazon EC2」のインスタンス起動を担う内部サブシステムが後続障害を引き起こしたという。
同社がこのEC2インスタンス起動障害への対応を続けている最中に、さらなる連鎖障害が発生したという。ロードバランサー「Network Load Balancer」において、サーバーの稼働状態を監視するヘルスチェック機能が機能不全に陥った。これが引き金となって、ネットワーク接続に関する問題が広範囲に波及。サーバーレス実行環境の「Lambda」、監視サービスの「CloudWatch」、そして一度は回復したDynamoDBを含む、多数の主要サービスが深刻な影響を受けた。
広範囲に及んだネットワーク障害を解決するため、AWSはまず午前9時38分にNLBのヘルスチェック機能を復旧させた。同時に、システム全体の安定を取り戻すため、EC2インスタンスの新規起動や、SQSキューを介したLambdaの処理、非同期のLambda呼び出しなど、一部の操作を意図的に一時制限(スロットリング)する措置を取ったとしている。
その後、AWSはネットワーク接続問題の解決を並行して進めながら、制限していた操作を段階的に緩和。復旧作業を進めた結果、午後3時1分(日本時間午前7時1分)までに、すべてのAWSサービスが正常な運用状態に戻ったと報告している。
報道のとおり、今回の障害でAWSを利用する世界中の多数のサービスが停止や機能不全に見舞われ、障害の影響は完全には解消されていない。AWSによると、同社の「AWS Config」「Redshift」「Connect」などの一部のサービスでは、障害発生中に処理できなかったメッセージが溜まっており、これらのバックログを解消するには、報告時点からさらに数時間かかる見込みだと説明している。AWSは後日、この連鎖障害に関する詳細な事後報告書を公開するとしている。
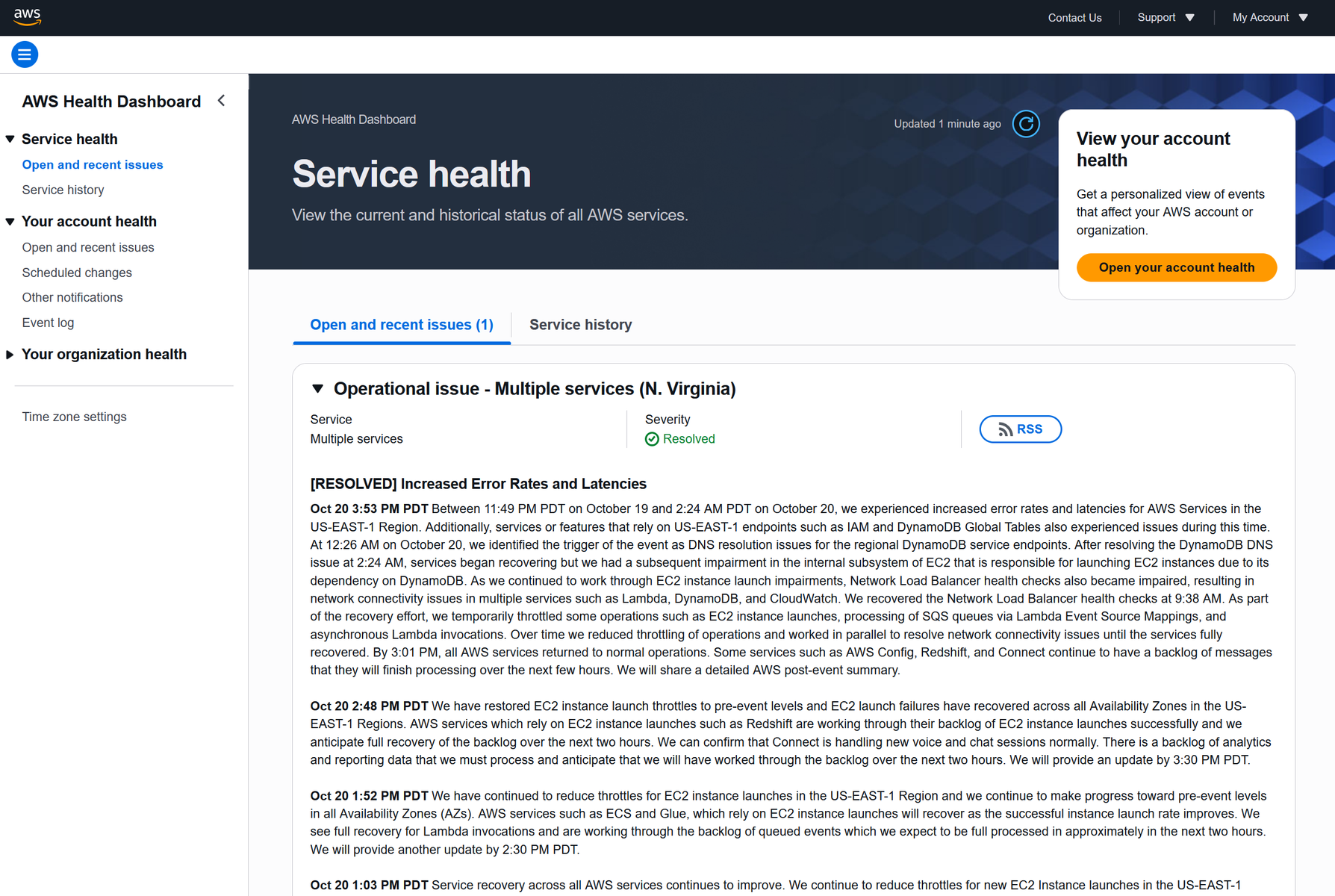 画面1:米AWSはAWSサービス群の状況を知らせる「AWS Health Dashboard」を通じて経過を報告している
画面1:米AWSはAWSサービス群の状況を知らせる「AWS Health Dashboard」を通じて経過を報告している拡大画像表示




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
