[製品サーベイ]
注目集めるHadoop─大量データを対象とした分散処理基盤、バッチ処理の高速化などに用途広がる
2010年9月8日(水)折川 忠弘(IT Leaders編集部)
企業が取り扱うデータは加速度的に増えている。これらの中に潜む有益な情報を競争力強化に役立てたいところだが、大量データを処理するには相応の性能を備えたシステムが不可欠。IT投資が限られるため、一歩を踏み出せないとする企業は少なくない。そこで注目を集め始めたのが、安価なサーバー群で分散処理する「Hadoop(ハドゥープ)」だ。
店舗から収集するPOSデータ、Webサイト利用者の行動/購買履歴、システムの操作ログ…。企業は今、多種多様なデータを大量に蓄積し、その量は増加の一途を辿っている。かつてデータ量の膨大さを形容した「テラバイト級」にもはや新鮮味はなく、今や「ペタ」単位で語られる時代だ。
集めたデータは商機拡大やリスクヘッジの貴重な材料であり、効果的な利活用が欠かせない。だが大量のデータを分析するには、相応の能力を備えたシステムが必要となる。投資したいのはやまやまだがIT予算には限りがある。何かブレークスルーはないものだろうか…。
大量データを分散処理で高速化
そこで注目を集めているのが「Apache Hadoop」である。その特徴は、PCサーバーなど安価なサーバーを複数連携させ、大量のデータを分散処理できることにある。グーグルが独自開発した技術が基になっており、現在はオープンソースソフトとして提供される。Hadoopを実装したサーバー群は、Hadoopクラスターと呼ばれる。
「1台の性能強化を図るスケールアップ型は、性能向上に伴い価格が飛躍的に高くなる。スケールアウト型のHadoopは、複数のサーバーが必要とはいえ、比較的安価なもので十分なことから総コストを抑えられる」。こう話すのは、早期からHadoopを活用してきたリッテルの清田陽司 上席研究員だ。
「サーバー台数にほぼ比例して性能が向上する。2000〜3000台という大規模なシステム構成でもスケールアウトできることが実証されている」(NTTデータ 基盤システム事業本部 システム方式技術ビジネスユニット OSSプロフェッショナルサービス シニアスペシャリスト 政谷好伸氏)という意見もある。
Hadoopを活用する企業が続々登場
こうした特徴に着目し、Hadoopを導入する国内企業が出始めた。
楽天は、Webサイトの利用者ごとに嗜好に合わせた商品を案内するレコメンデーションや、売り上げランキングを集計するのにHadoopを利用する。「多大な商品/購買情報を解析するのに、26時間かけていたバッチ処理を4時間半に短縮できたという効果が出ている」(楽天 広報)。
三菱UFJインフォメーションテクノロジーは100コア相当のサーバーを用意し、Hadoopの性能を検証中だ。「今後はグループ各社の業務システムにHadoopを適用し、大量の明細データの処理に活かしたい」(三菱UFJインフォメーションテクノロジー ITプロデュース部 千貫素成部長)。
料理レシピの紹介サイトを運営するクックパッドは、利用者が入力した検索キーワードを月別に把握できる環境をHadoopを使って整え、本格利用を始めている。今後は他の用途にも積極的に応用するという。
分散処理前提のファイルシステム
大量データを分散処理するHadoopは、大きく2つの技術要素から成り立っている。データの保管場所となるファイルシステムの「HDFS(Hadoop Dis- tributed File System)」。そして、データ処理フレームワークの「Map Reduce」だ。
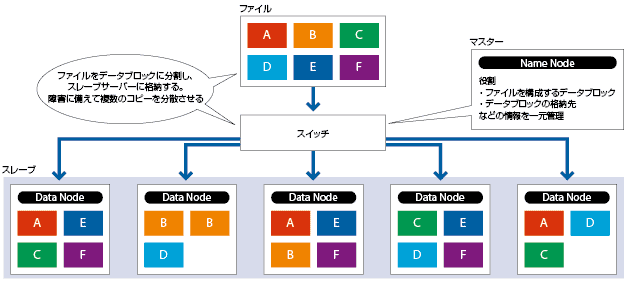
HDFSは、Distributedの名の通り、分散処理することを前提に設計されたファイルシステムである。データを細かい断片(データブロック、デフォルトでは64MB)に分割した上で、Hadoopクラスターを構成する複数のPCサーバー(DataNode)のローカルディスクに書き込む。クラスターの中にはNameNodeと呼ぶ単一のマスターサーバーがあり、データブロックの格納先の情報を一元管理している。
耐障害性を高めるため、各データブロックを書き込む際には、そのコピーが複数のPCサーバーに分散保存されるようになっている。あるデータブロックがハード障害で消失しても、別のサーバーにあるコピーで代替するわけだ。一連の仕組みは、NameNodeと各サーバーの通信によって自律的に行われる(図1)。
MapとRuduceの2段階でデータを処理
MapReduceは、HDFSと連携して機能するデータ処理フレームワークだ(図2)。MapとReduceという処理を順次2段階に分けて実行する。
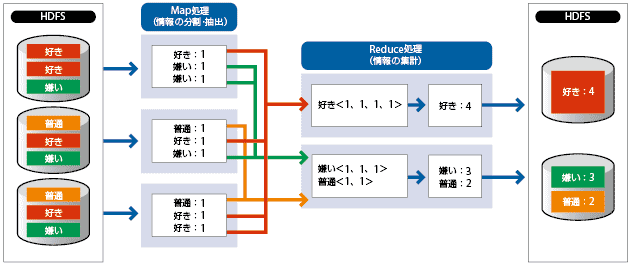
Map処理では、大元のデータを細かく分割し(HDFSと連携)、個々のデータブロックに目的とする処理を施した結果を中間ファイルとして出力する。続くRuduce処理では、複数の中間ファイルをまとめて集計し最終的な答えを出す。
一見、まどろこしくも感じるが、(1)Map処理とReduce処理の独立性、(2)Map処理同士の独立性、(3)Reduce処理同士の独立性−を持たせることで、複数のPCサーバーによる分散処理をしやすくしている。
HDFSと同様に単一のマスターサーバー(JobTracker)が全体の動きを制御し、実際の処理はHadoopクラスターの各サーバーで実行する。HDFSと密連携し、例えば1つのMap処理は、その対象となるデータブロックを格納しているサーバーに可能な限り割り振る。クラスター内のサーバー間通信を極小化し、全体の処理速度を速めるためだ。
仕様上は、クラスターに様々なスペックのサーバーが混在しても運用できるが、できるだけ性能差のないサーバーを揃えた方が良い。「サーバーの性能に偏りがあると、処理の遅延や失敗を引き起こしやすくなる。事前のチューニングで性能の差異を吸収することは技術的に可能だが、後々の運用を考えるとプロセサの搭載コア数、メモリーとディスクの搭載容量をある程度同等にすることが望ましい」(NTTデータ 政谷氏)。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- 注目のメガネ型ウェアラブルデバイス[製品編](2015/04/27)
- メインフレーム最新事情[国産編]NEC、日立、富士通は外部連携や災害対策を強化(2013/09/17)
- メインフレーム最新事情[海外編]IBM、ユニシスはクラウド対応やモバイル連携を加速(2013/09/17)
- データ分析をカジュアルにする低価格クラウドDWH(2013/08/02)
- 「高集積サーバー」製品サーベイ─極小サーバーをぎっしり詰め込み、用途特化で“非仮想化”の強みを訴求(2013/07/23)



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
