モルフォグループのモルフォAIソリューションズ(モルフォAIS)は2023年12月19日、大規模言語モデル(LLM)に学習させる日本語データセットの生成サービスを提供開始した。独自のLLMを構築を検討する企業などに向けて提供する。画像からAI-OCR(光学文字認識)でテキストを抽出してLLM学習用の日本語データセットを生成する。データ化されていない文書を学習用に活用できるようにして、高品質な日本語LLMの構築を支援する。
モルフォAIソリューションズ(モルフォAIS)は、大規模言語モデル(LLM)に学習させる日本語データセットの生成サービスを提供開始した。独自のLLMを構築を検討する企業などに向けて提供する。画像からAI-OCR(光学文字認識)でテキストを抽出してLLM学習用の日本語データセットを生成する。データ化されていない文書を学習用に活用できるようにして、高品質な日本語LLMの構築を支援する。(図1)。
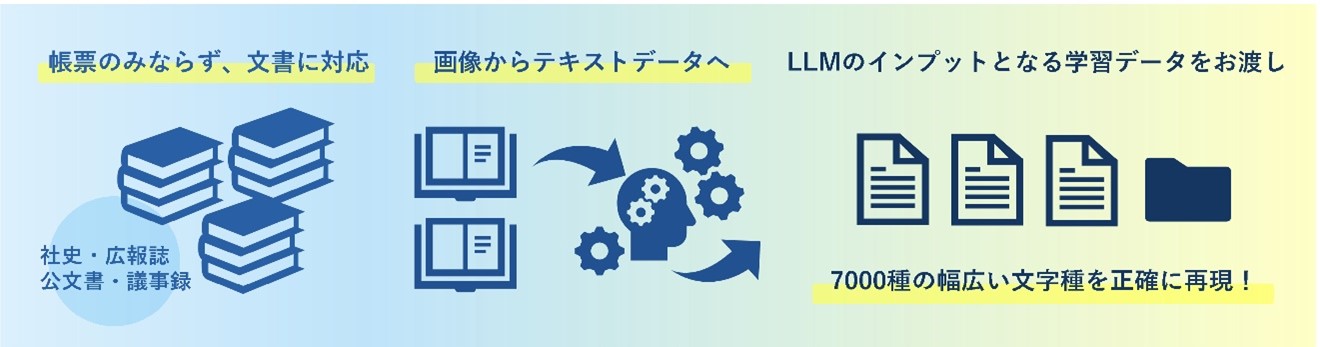 図1:LLM向けの日本語データセットを生成するサービスの概要(出典:モルフォAIソリューションズ)
図1:LLM向けの日本語データセットを生成するサービスの概要(出典:モルフォAIソリューションズ)拡大画像表示
「良質な日本語LLMの構築にあたっては多様な日本語データを収集する必要がある。しかし、収集可能な日本語データの大半はインターネット普及後の1990年以降のもので、それ以前の文書(社史・広報誌・公文書・議事録等の保存文書)の多くがデジタルデータになっていない」(モルフォAIS)。そのため、独自のLLMを構築しようとしても、学習元が公開済みのデータセットの活用に限定されるという(図2)。
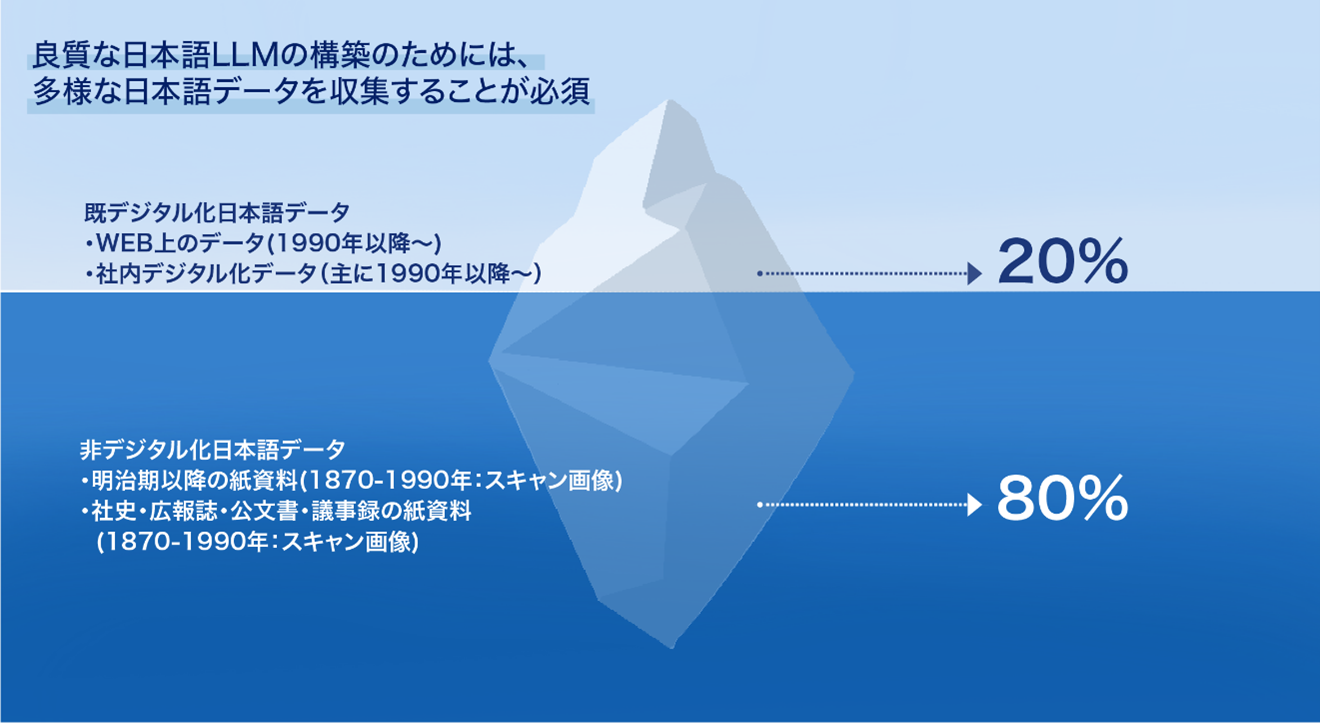 図2:良質な日本語LLMの構築のためには、これまでデジタルデータ化されていなかった過去の文書を学習する必要がある(出典:モルフォAIソリューションズ)
図2:良質な日本語LLMの構築のためには、これまでデジタルデータ化されていなかった過去の文書を学習する必要がある(出典:モルフォAIソリューションズ)拡大画像表示
また同社は、市販のOCR製品の多くは請求書や領収書など定型的なフォーマット向けであり、縦書き、横書き、多段組など多様なレイアウトと文字種で作成された文書のテキスト抽出は不得意という課題を指摘している。
同社が提供する新サービスでは、市販のOCR製品が苦手とする文章の読み順まで含めてテキストを抽出でき、読み取り可能な文字種は約7000種類で複雑な漢字も読み取れるという。「自組織が保有する文書のスキャン画像から日本語LLMの学習用に使える品質でデータを抽出してデータセットを生成できる」(同社)。
先行事例として、国立国会図書館、沖縄県豊見城市、イタリア・ボローニャ大学、順天堂大学、滋賀県立図書館、大手新聞社などが同サービスを活用している。なお、モルフォのOCRソフトウェア「FROG AI-OCR」は国立国会図書館の「NDLOCR」をコアエンジンとして利用している。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
