データ活用によって事業の課題を解決し、ビジネスの拡大を実現するには、データ活用戦略をデザインし、組織を横断してデータを統合する必要がある。しかし、それには多くの壁が立ちはだかる。2024年3月8日に開催された「データマネジメント2024」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)のセッションにウイングアーク1stの山本宏樹氏が登壇し、組織横断でのデータ活用を阻む課題と、その解消法を語った。
提供:ウイングアーク1st株式会社
IPA(独立行政法人情報処理推進機構)が発行した「DX白書2023」(2023年2月9日公開)の「データの利活用の状況(日米比較)」によると、「全社でデータの利活用を進めている」と回答した企業は、米国では全体の29%だが、日本は19%と米国を大きく下回っている。一方、部門ごとの利活用は日本が36%で、米国の23%を上回っている。
またETLツールやデータHUB、データ統合ツールなどの技術の活用状況の比較では、全社利用と部門利用のいずれにおいても日本は米国を下回っている。こうした結果を示しつつ、ウイングアーク1stの山本 宏樹氏は、「日本企業は組織横断のデータ統合が進んでいない」と語る。
 ウイングアーク1st株式会社 Data Empowerment事業部 DEサービス統括部 統括部長 山本 宏樹 氏
ウイングアーク1st株式会社 Data Empowerment事業部 DEサービス統括部 統括部長 山本 宏樹 氏 しかし、そんな日本でもDXの重要性が叫ばれ始めた頃から、組織を横断したデータ活用への期待値が高まっている。
「従来の“モノ売り”の視点では、個々の業務効率を重視したデータ活用が主流だったかもしれないが、 “コト売り”の視点で、顧客体験を重視したデータ活用ニーズの期待値が増し、必要性も生じている。たとえば生産者が最終消費者を意識しつつ、どのような製品を開発すべきかといった、バリューチェーン全体のデータを統合した組織横断でのデータ活用が求められるようになってきた」と山本氏は変化を語る。
組織横断でのデータ活用を阻む「壁」
ウイングアーク1stではデータ活用レベルの成熟度を次のように定義している(図1)。
 図1:データ活用レベルの成熟度モデル
図1:データ活用レベルの成熟度モデル拡大画像表示
- レベル1 個人でのデータ活用
- レベル2 チームや部門内など局所的なデータ活用
- レベル3 仕組み化された組織横断のデータ活用
- レベル4 ビジネス差別化を実現するデータ活用
- レベル5 業界や社会課題の解決を実現するデータ活用
日本企業が乗り越えなくてはならないのは、レベル2からレベル3に至る「壁」だと山本氏は語る。
データ活用をスモールスタートする難しさ
レベル2からレベル3に向かう過程で、実際にどんな「壁」に直面するのだろうか。もともと、日本では給与計算や財務会計など個別業務を最適化することを目的にシステム導入を行った企業が多く、データがサイロ化しやすいだけでなく、データ構造を領域横断に繋げるハードルが高いという問題が根本にある。単にデータウェアハウスやBIツールを導入しても、理想的なデータ活用は困難だ。加えて、現状維持を重視した継ぎ足しのシステム開発を重ねてきた弊害も出てきている。
その中でよくあるのは、データ活用をスモールスタートで始めたケースだ。データ活用は費用対効果が説明しづらいこともあり、扱いやすいテーマから始めて、次第により大きな効果を出せるテーマに着手していき、小さな成功体験を繰り返しながら活用範囲を広げていくという意味では、正しいアプローチだ。
しかし個別最適の繰り返しでは各データマート間でデータが揃わず、データ品質が保てない。バリューチェーン全体のデータを統合的に活用したいというニーズが高まった際には、領域横断のデータ活用のためのデータ統合が改めて必要になる。
当然ながらすべての基盤を再構築するには相当の労力が必要だ。「最初からデータ活用の最終目的をイメージし、それを意識してスモールスタートすれば良いが、現実は難しい」と山本氏は指摘する。
データ統合の3つの課題
システム間のデータ統合を進める中でもさまざまな課題が発生する。その代表例は次の3点だ。
- データの仕様……システム間のコード体系や仕様の違いによって、蓄積されたデータがスムーズに紐づかない
- データ欠損時の考慮……すべての部門やグループ会社が連携するのではなく、一部、連携されないデータが存在し、網羅性がない。代替できるデータソースで補填する必要がある
- 例外への対応……日付項目に不正な値が入ったり、数値項目に数字以外の表現が含まれたりなど、過去の慣例や個別要請などにより、例外的なデータの発生が存在する
こうしたデータ統合時に直面する課題の解決策として、山本氏は2つのポイントを挙げた。1つはデータ抽出・統合ロジックの標準化である。取り扱いやすいテーマや目的ごとに汎用的なデータモデルを設計し、データ抽出・加工ロジックを標準化する統合領域を設け、データ品質を均質化する。これにより、データの深い知見を必要とせずデータを扱うことが可能となり、保守運用の観点でも有効だ。
もう1つはデータを抽出・貯める領域とデータ活用を目的としたデータ統合領域を分離することだ。前者のデータウェアハウスにはシステム的な視点でデータを蓄積するが、後者のデータ統合領域については、データスチュワードが業務視点で扱いやすい状態に設計することがポイントとなる。
データスチュワードに必要とされるデータ分析基盤とは
ウイングアーク1stの「Dr.Sum」はデータスチュワードに必要とされる特徴を有するデータ分析基盤だ。山本氏は「Dr.Sum」の特徴として、下記の5点を挙げる(図2)。
- 用途に応じてクラウド版とオンプレミス版が選べ、定額利用ができること
- SQLが分からなくてもノーコードで開発できる
- 大量データも高速処理できる
- マニュアルが日本語でサポート体制も万全
- DWH(Data Ware House:データウェアハウス)や他社のBIツールとの接続も可能
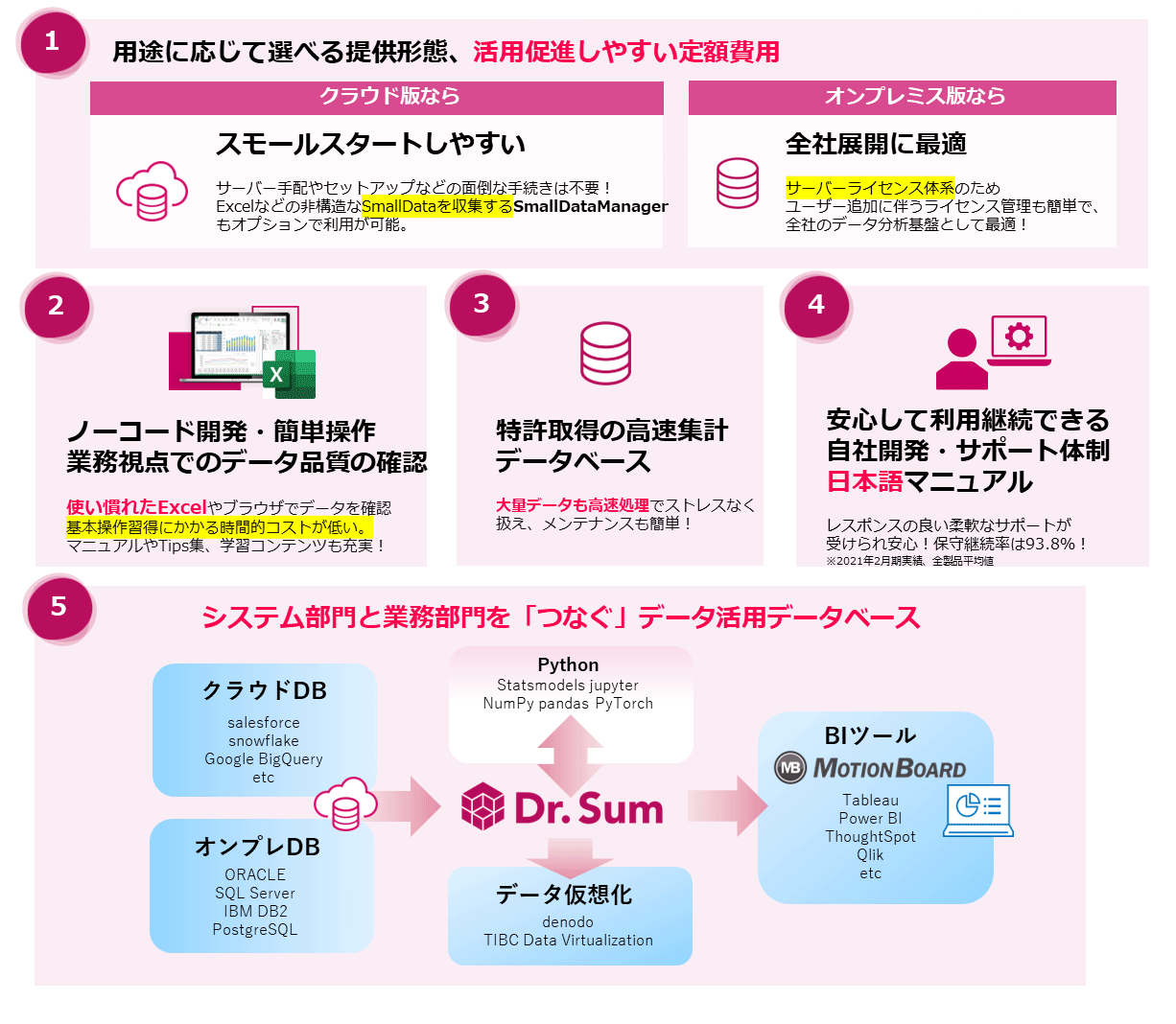 図2:「Dr.Sum」の特徴
図2:「Dr.Sum」の特徴拡大画像表示
データ活用の継続性に着目した「Dataring」とは
ウイングアーク1stでは、データ活用の取り組みは一過性のものではなく、地道に継続してこそビジネスに貢献できるものになると考えている。単に複数システムのデータを一元管理するだけでは不十分で、データマネジメントなどデータの品質を維持、高めるための継続的な取り組みは欠かせない。ウイングアーク1stはそのデータ活用の継続性にフォーカスし、その環境づくりを製品、サービス、エコシステムで支えるためのオファリングモデルとして「Dataring(データリング)」を提供している。
また、ウイングアーク1stが提供するデータマネジメントについては、「データ整備」と「データ活用」の2つの領域で捉え、「データ活用」領域から整備を行っていく点が特徴的だ。
こうした考えに基づき、データ活用戦略の構想支援とデータ活用組織の設計支援を行う。データ活用戦略の構想支援については、現状の把握やアセスメント、経営課題や事業戦略を鑑み、データ活用のあるべき姿を明確にする。データ活用組織の設計支援については、データ総研との業務提携により、ゴールやミッション、体制や役割の策定を支援する(図3)。
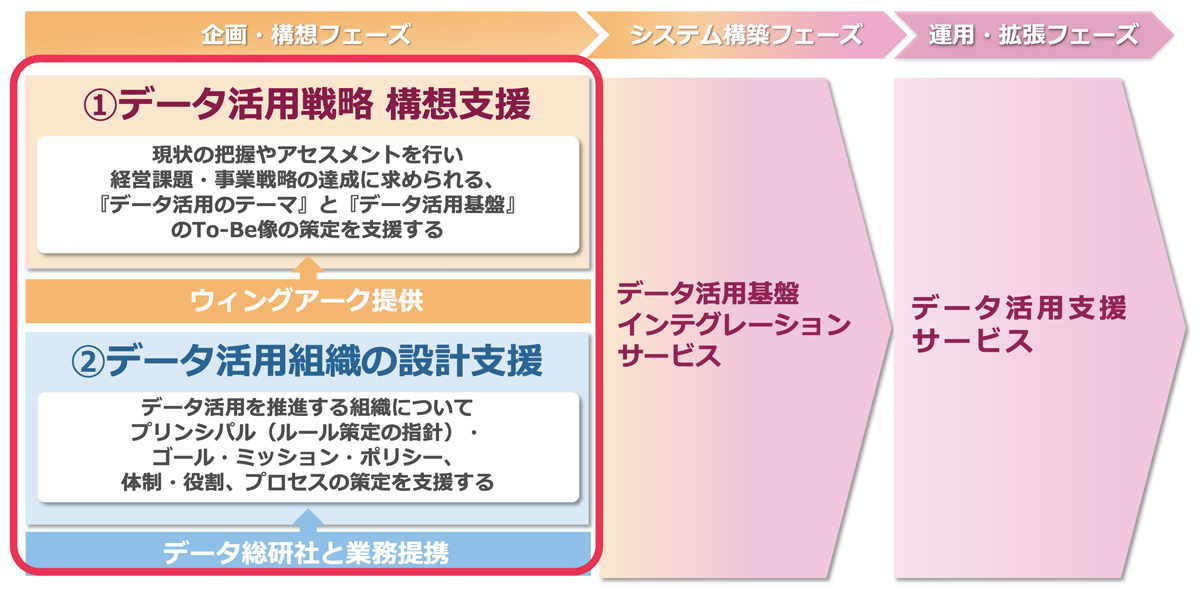 図3:ウイングアーク1stのデータマネージメントサービスの概要
図3:ウイングアーク1stのデータマネージメントサービスの概要拡大画像表示
ウイングアーク1stでは、生成AI技術の活用にも取り組んでおり、短い時間で効率化された体験を提供することを目指している。「Dr.Sum Copilot technical Preview版」は、自然言語からSQL、Pythonスクリプトを生成する。「ゼロから記述するのは大変」「文法を忘れてしまった」など、ある程度SQLやPythonを理解している人を支援するツールだ。
他にも生成AIを活用して利用者や運用者の負荷を軽減させるツールなど、「データ活用を続けた先の課題解決に貢献するソフトウェアを計画中」と山本氏は語った。
●お問い合わせ先

ウイングアーク1st株式会社
URL:https://www.wingarc.com/
- データドリブン経営の成否はデータの信頼性に左右される(2024/06/03)
- MDMをスモールスタート・アジャイル型で! NTTコム オンラインが提唱するデータマネジメントのアプローチ(2024/05/31)
- DX支援のための先進技術は自社を“実験場”に─データ仮想化や生成AIの意義と効果とは?(2024/05/09)
- 「おもてなしDX」の推進で、財務データを活用したITコスト最適化に臨む(2024/04/25)
- 生成AI時代に欠かせないデータの集約管理をFlashBladeが具現化する(2024/04/24)




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
