[インタビュー]
「低品質なデータが大惨事を引き起こす」─AI時代に専門家が訴えるデータ品質の重要性
2024年8月19日(月)愛甲 峻(IT Leaders編集部)
セルフサービスBIやデータ統合の製品を中心に、顧客のデータ活用の高度化に注力してきた米Qlik(日本法人:クリックテック・ジャパン)。近年の同社は新たなサービスの提供や企業買収を通じて、顧客のAI活用支援の姿勢を鮮明にしている。その狙いや戦略について、同社シニアディレクター/マーケットインテリジェンスリードのダン・サマー(Dan Sommer)氏に聞いた。
データと分析が不可分なAI時代のデータ基盤
──生成AIの登場を受けて、企業にとってデータはますます重要性を増していると思います。Qlikが現在どのような点に注力しているのか教えてください。
ダン・サマー(Dan Sommer)氏(写真1):AIの時代が到来し、データとアナリティクスがますます不可分になっています。そのため、私たちは過去数年にわたり、企業のデータ活用を包括的に支援するエンドツーエンドのサービス構築に努めてきました(図1)。
多様化する構造化/非構造化データに加えて、データの所在も高度に分散化しており、データ統合は多くの企業にとっての課題です。そのため、当社は2023年にETLやデータ統合のリーディングベンダーである米Talend(タレンド)を買収し、ラインアップを強化しています。
 写真1:米Qlik シニアディレクター/マーケットインテリジェンスリードのダン・サマー氏。以前は米ガートナーでアナリストとして10年間勤務し、IT業界で20年以上の経験を持つ
写真1:米Qlik シニアディレクター/マーケットインテリジェンスリードのダン・サマー氏。以前は米ガートナーでアナリストとして10年間勤務し、IT業界で20年以上の経験を持つ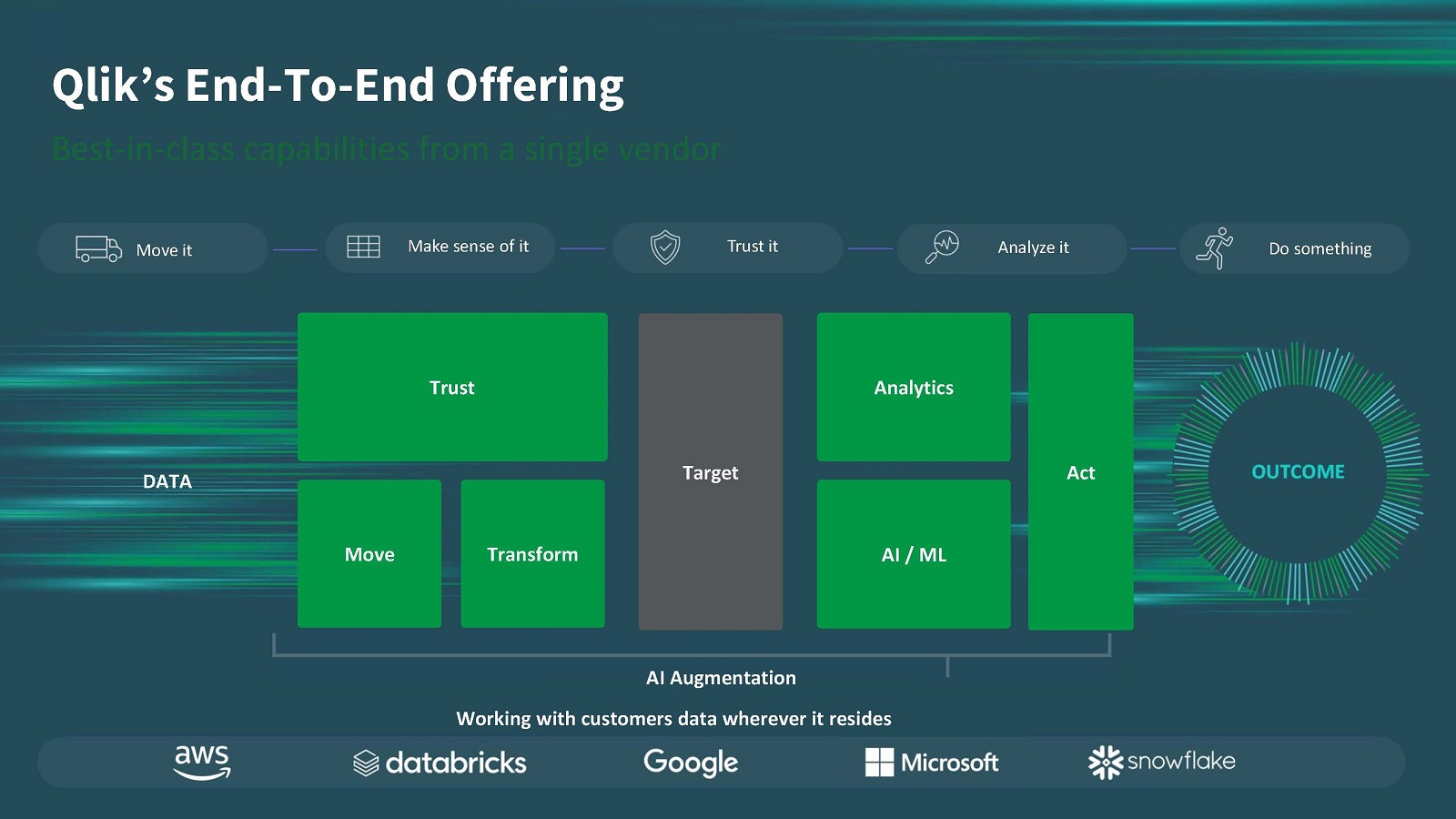 図1:エンドツーエンドのサービスラインアップ(出典:Qlik)
図1:エンドツーエンドのサービスラインアップ(出典:Qlik)拡大画像表示
現在、顧客のシステム環境は、マルチクラウド・マルチデータソースが当たり前になっていますが、それらの主要なテクノロジースタックに対応し、サービスを提供できるようにしていることも当社の強みです。メインフレームのようなレガシー環境からモダンなクラウド環境へデータをリアルタイムに複製・移行するようなケースに対して、業界最高水準のサービスを提供できると自負しています。
また、AI活用の浸透とともに、データ品質の重要性が10倍、100倍にも高まると考えています。誤った情報が深刻な事態につながることもあり、データの信頼性もこれまで以上に大切です。そこで、当社はデータ品質管理やデータプロファイリングに関する技術への再投資を進めています。
アナリティクスやAI/マシンラーニング(機械学習)の領域では、複雑な分析を状況に応じ信頼できる形で可能にすることや、データマネジメントやデータサイエンスに関するさまざまなタスクを直観的に実行できるようにすることに努めています。
一方で、アクションを伴わない分析の価値は限定的です。そこで、私たちはアプリケーションにAI機能を埋め込むことで、データから得られる洞察を適切なタイミングで提供し、アクションを促すことにも注力しています。
──Qlikは顧客のAI活用をデータの側面から支援するという方針を打ち出しています。2023年9月には、データ活用に資するAIのフレームワーク「Qlik Staige」を発表しています。その概要や狙いを教えてください。
Qlik Staigeは、QlikがAI活用をどう考えているかを表したフレームワークです。3つの要素からなり、顧客にどのような価値を提供できるかを示しています(図2)。
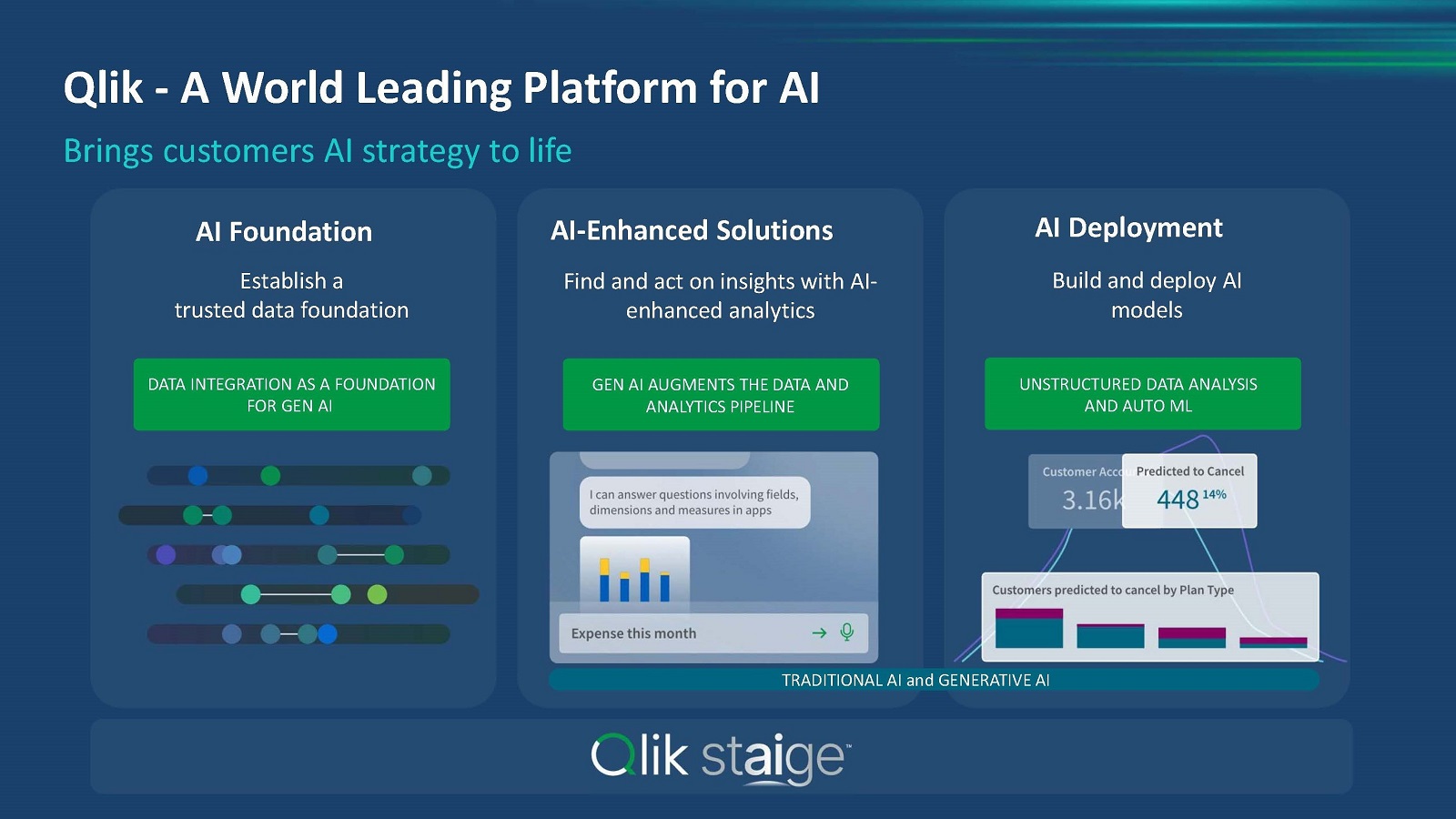 図2:Qlik Staigeの概要(出典:Qlik)
図2:Qlik Staigeの概要(出典:Qlik)拡大画像表示
1点目はAI基盤としての要素です。AIの品質は供給されるデータに依ります。当社は複数のAIモデルを組み合わせて利用できることに加え、多様なデータソースに対応し、AIモデルがある場所にリアルタイムでデータを動かせるという他にないサービスを有しています。
2点目はデータ統合/分析のためのAIソリューションで、生成AIを含めたAIにより、ETLスクリプトやデータパイプラインの構築を支援します。データ分析では、拡張分析(Augmented Analytics)機能により、インサイトの導出やビジュアライズ、ダッシュボードの作成などを、AIを用いて行えるようにします。
3点目はAIモデルの導入支援です。私たちはAutoML(自動機械学習)機能や、AIベンチャーの米Kyndi(キンディ)の買収によって獲得した非構造化データの活用を支援する技術を有しています。これらにより、高度な分析やデータサイエンス、RAG(Retrieval Augmented Generation:検索拡張生成)構成の構築を容易にします。
──2023年末から2024年初にかけて、KyndiとMozaic Data(モザイクデータ)という米国のAIベンチャー2社の買収を立て続けに発表しています。いずれも顧客のAI活用支援を強化するための買収だと思いますが、それぞれの狙いを聞かせてください。
Kindiは、構造化/非構造化を問わずにデータを取り込んでAIからの回答精度を高めるための技術です。背景として、組織内のデータのうち、80%はドキュメントなどの非構造化データが占める中、企業は長年こうした非構造化データの解析を試みるも、十分な効果を得られないでいました。生成AIが台頭してからは、RAGやベクトルデータベース、ナレッジグラフなどへの取り組みが始まりましたが、複雑さや高コストなどの課題があります。RAGの場合は、同じ質問に対して毎回異なる回答が返ってくるという問題も浮上しています。
そこで当社は、非構造化データを基に、同じ質問に対して常に同一の精緻な回答を返せるKindiのナレッジエンジンに価値を見出しました。構造化データと非構造化データを組み合わせて活用できることも強みです。
Kindiの獲得により、Qlikのユーザーは自然言語による質問で、構造化データと非構造化データの両方を基にした正確な回答を得られるようになります。また、BIのために構造化/非構造化の両方のデータを探索するケースでも、Kindiの技術がそれを助けます。
●Next:AI時代は「低品質なデータが大惨事を引き起こす」
会員登録(無料)が必要です


- 1
- 2
- 3
- 次へ >
Qlik / Talend / 生成AI / RAG / 非構造化データ / データ統合 / BI / ETL / セルフサービスBI / データカタログ / データサイエンティスト / データプロダクト / メタデータ管理


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
