[事例ニュース]
朝日新聞社、LLMを参照する取材音声文字起こしツール「ALOFA」をサーバーレスで構築
2024年9月25日(水)日川 佳三(IT Leaders編集部)
朝日新聞社(本部:大阪府大阪市)は、記事制作時に音声データから文字を起こす社内ツール「ALOFA」を構築し、社内の記者が活用している。今後、社外への展開も検討している。生成AIサービス「Amazon Bedrock」を採用し、「AWS Lambda」でAWS上のサーバーレス環境としてシステムを構築・運用している。2024年9月25日、取り組みの内容をAWSジャパンの公式ブログで公開した。
朝日新聞社は、記事制作時に音声データから文字を起こす社内ツール「ALOFA」を構築し、社内の記者が活用している。今後、社外への展開も検討している。
アマゾン ウェブ サービス ジャパン(AWSジャパン)の技術を活用して構築した。ALOFAの開発に至った背景や生成AIサービスを含めたシステム構成など、取り組みの内容を、朝日新聞社とAWSジャパンの担当者が共同で、Amazon Web Servicesブログで紹介している。
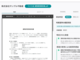
ALOFAを開発した背景として朝日新聞社は、記事制作の現場において、取材音声データの文字起こしに多大な時間と手間がかかることを挙げている。同社によると、1時間の音声ファイルの文字を起こすのに、平均2.5時間かかっているという(図1)。これを半自動化するためにALOFAの開発に着手した。
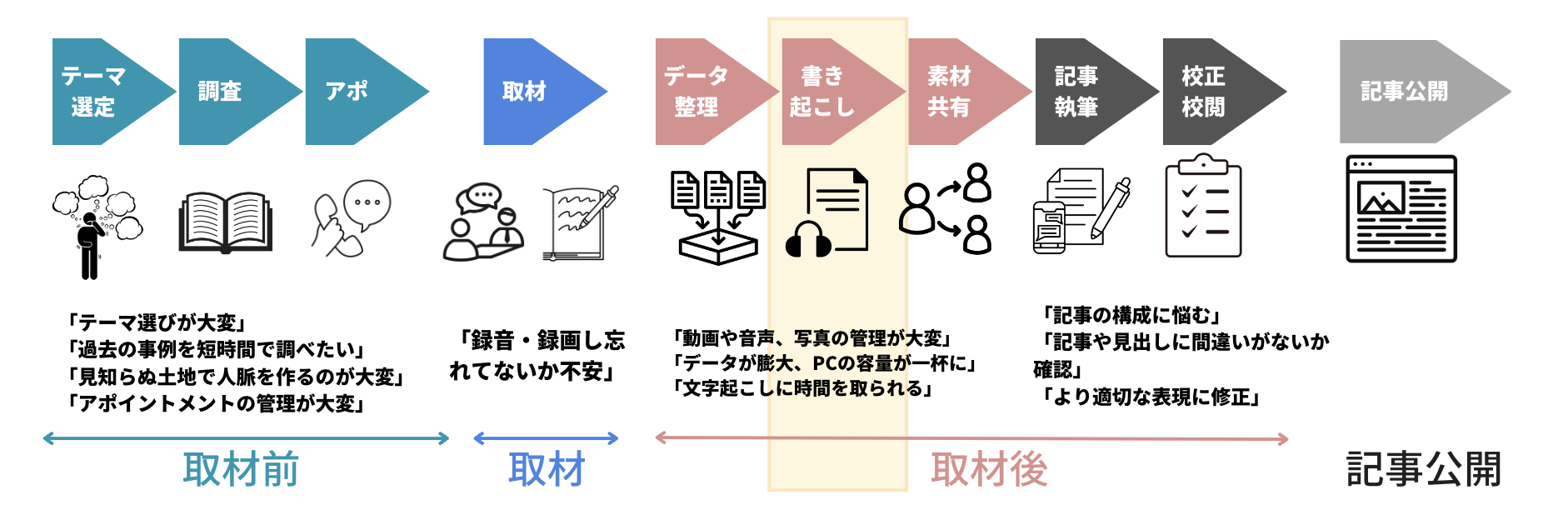 図1:取材準備から記事公開に至るまで(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)
図1:取材準備から記事公開に至るまで(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)拡大画像表示
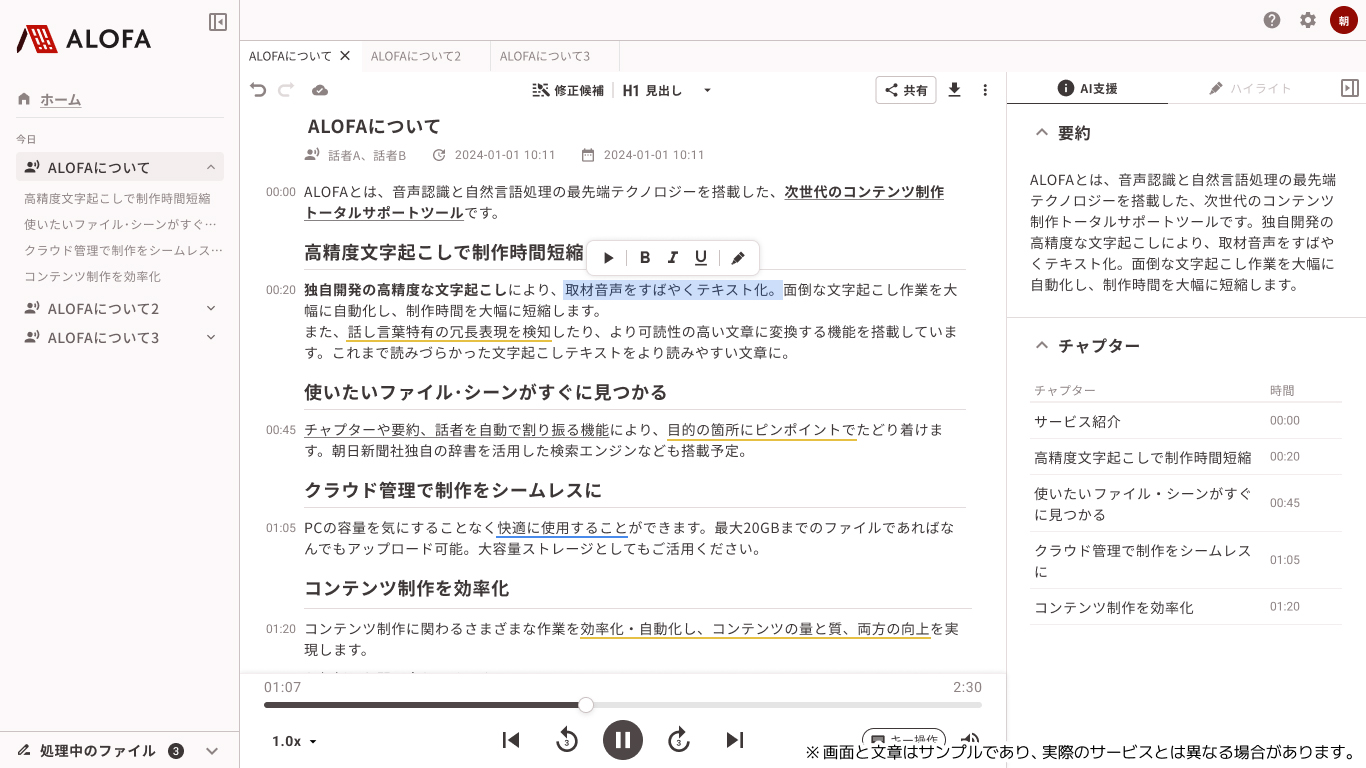 画面1:文字起こしツール「ALOFA」の画面イメージ(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)
画面1:文字起こしツール「ALOFA」の画面イメージ(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)拡大画像表示
ALOFAの専用エディタ(画面1)では、話者を識別する機能、話し言葉特有の冗長表現を検知・削除する機能、生成AIを活用した要約機能、チャプター生成機能を備えている。「音声を聴きながらでも、書き起こされた文章を細かく修正することができる」(同社)という。
ALOFAの稼働基盤は、生成AIサービス「Amazon Bedrock」を採用し、「AWS Lambda」でAWS上のサーバーレス環境として構築・運用している。上述の要約やチャプター生成をBedrockによって実現している。大規模言語モデル(LLM)は、業務用途ごとに複数のモデルを検証して適したものを採用したという(図2)。
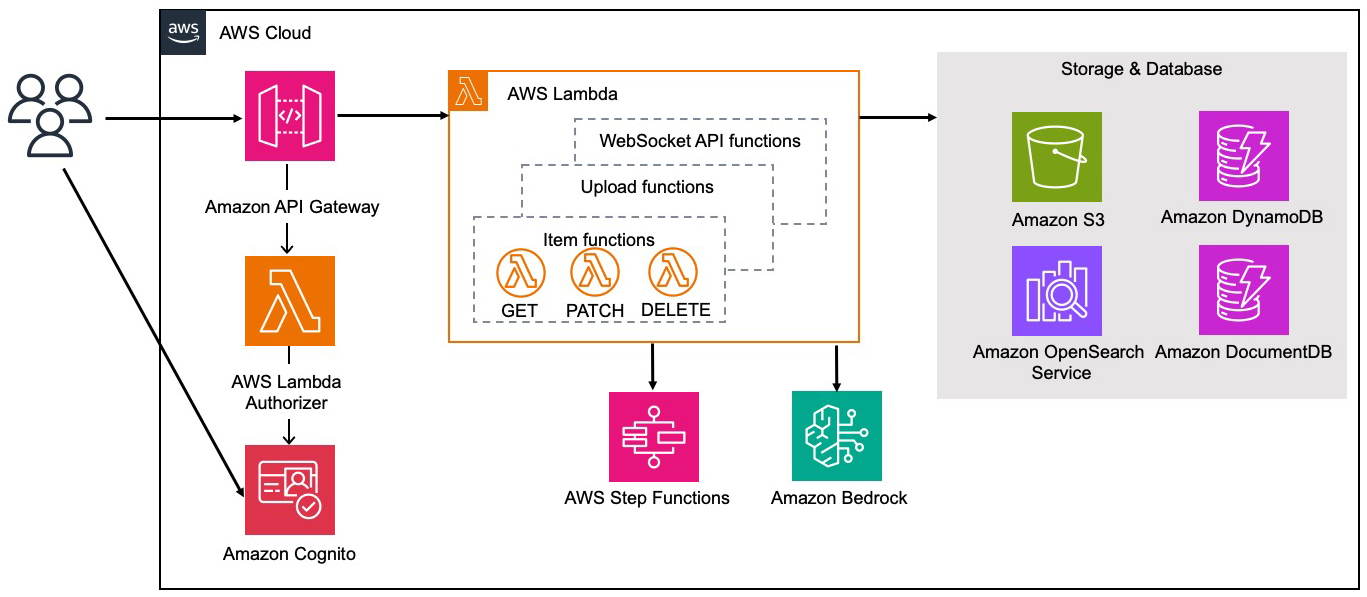 図2:音声文字起こしツール「ALOFA」のシステム構成(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)
図2:音声文字起こしツール「ALOFA」のシステム構成(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)拡大画像表示
文字起こしのための音声認識モデルはマシンラーニング(機械学習)を使って内製で構築。推論部分はC++で実装し、GPU非対応のLambdaサーバーレス環境でも高速に推論できるようにしている。また、開発容易性を考慮し、C++のコードを、C++の言語仕様を意識することなくPythonから利用可能にしている。モデルのサイズは約1.5GBで、これをコンテナイメージに組み込んでいる。
Bedrockを並列で複数呼び出すユースケースに対しては、急激にリクエストが増えた場合でも適切なレスポンスを確保するため、Lambdaから複数リージョンのBedrockを呼び出すアーキテクチャを採用した(図3)。
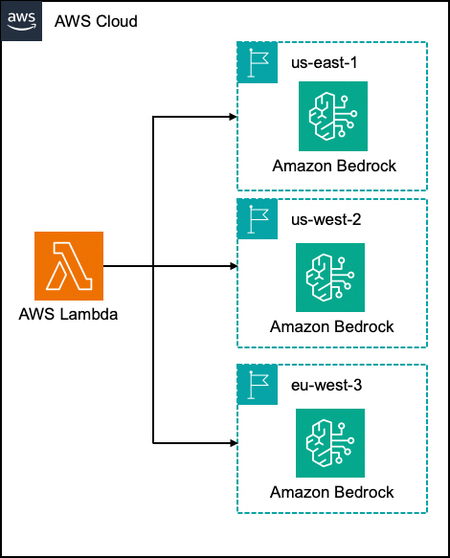 図3:複数リージョンでAmazon Bedrockを利用(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン)
図3:複数リージョンでAmazon Bedrockを利用(出典:朝日新聞社、アマゾン ウェブ サービス ジャパン) 


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
