性能を最大限に引き上げるインメモリー技術と自動チューニング──。検索や更新のパフォーマンス(性能)をいかに高めるかは、昔から変わらぬDBMSの重要なテーマである。情報システムの大規模化や複雑化が進む一方の現在、その重要性は一層高まっている。パート4ではインメモリー技術やSQL文の自動チューニング機能といった「パフォーマンス」の側面から、Oracle Database11g R2の技術を解説する。
Oracle Databaseは信頼性を損なわずに拡張性や可用性を高めるのと並行して、パフォーマンスの向上に力を入れてきた。増大する一方のデータを、高速に更新・検索するニーズに応えるのと同時に、大容量化・低価格化が進む半導体メモリーの利点を享受できるようにするのが骨子だ。
ここではその主要技術として、(1)メモリー上にDBを展開して処理を高速化する「TimesTen In-Memory Database(IMDB)」、(2)クエリー処理を分割して並列で実行する「In-Memory Parallel Query」、(3)データウェアハウス(DWH)アプライアンス「Oracle Exadata」、(4)SQL文などの自動チューニング機能、について解説する。
機能改良・強化を重ねOracleとの親和性向上
TimesTen IMDBは、2005年6月に企業買収によって得たインメモリーDB製品である。買収後、4年の開発期間をかけて、Oracle Database とのデータ型の共通化やSQL構文の互換性の強化、Oracle DatabaseのネイティブAPIであるOCI(Oracle Call Interface)のサポートや、ODBC/JDBCだけでなくPro*C、PL/SQLといったオラクル独自の開発言語のサポートなどを実施してきた。これによりOracle Databaseを使用しているアプリケーションの多くで、TimesTen IMDBが使えるようになった。
TimesTen IMDBは単独で稼働するが、Oracle Databaseと連携させることもできる。「Oracle In-Memory Database Cache」がそのための機能であり、Oracle Databaseの表に対する「キャッシュ表」をTimesTen IMDB上に定義すると、自動的に双方のデータベースの同期をとる。この機能は、Oracle Databaseのオプション製品として提供している。
ボトルネックを解消しOLTP処理を高速化
ではTimesTen IMDBとOracle Databaseは、どう違うのだろうか。「前者はディスクではなく、メモリー上にデータを展開するから処理が高速」と考えるのは間違いではないが、高速化の仕組みを正確に理解したとは言えない。
図4-1を見て頂きたい。TimesTen IMDBは、一般的なDBMSが抱えるいくつかのボトルネックを解消して、パフォーマンスの向上を実現しているのだ。1つがディスクへの入出力を意識しないで済むので、データベース・ブロック単位でのデータ管理が不要になること。事実、IMDBの索引のリーフにはメモリー上の物理アドレスの情報が格納されており、ダイレクトにデータにアクセスできる。
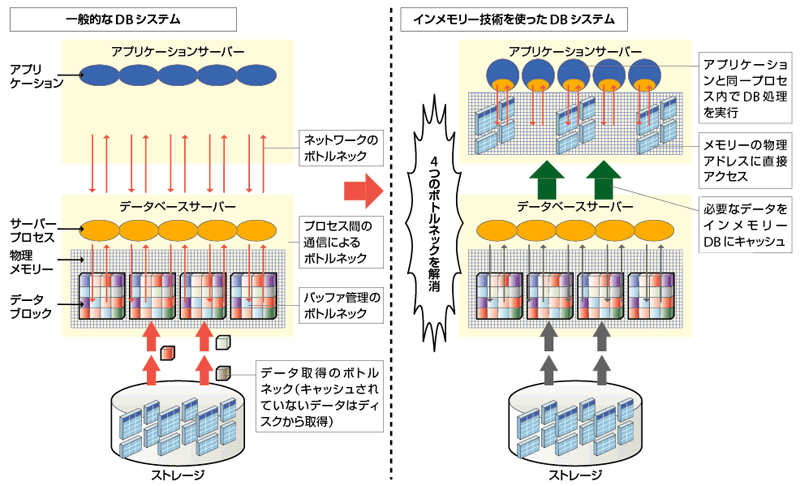
インメモリーDBは文字通りアプリケーションサーバーのメモリー上にDBサーバー内のデータを展開する。アプリケーションサーバーとDBサーバー間、DBサーバー内のプロセス、ディスクアクセスなど各種ボトルネックを解消することでOLTP処理の高速化を実現する
これに対し、一般的なDBMSはメモリーにデータをキャッシュする仕組みを備え、特に高速処理を要求されるOLTPでは100%に近いデータをメモリー上にキャッシュして処理を行うことができる。しかし、ブロック単位でのデータ管理が必要なゆえに論理IDから物理アドレスへのアドレス変換のオーバーヘッドが生じるのである。
第2が、アプリケーションサーバー上にIMDBを配置することで、アプリケーションと同一のプロセスでデータベース処理を行えること。一般的なDBMSにある、DBサーバーとのプロセス間通信のボトルネックやネットワーク通信による遅延を排除できるわけだ。当然、バッファ管理などのオーバーヘッドも少なくできる。こうしたことにより、IMDBでは1件の処理あたりの実行命令数が、そうでないDBMSの約10分の1程度になる。
ただし、あらゆる処理を高速化できるわけではない点に注意する必要がある。TimesTen IMDBは索引を使った検索処理を高速に実行することを前提に開発されており、例えば全文検索やアドホックな検索には向かない。特にデータウエアハウスのように、一度に大量のデータにアクセスする用途では、並列処理が可能なOracle Databaseの方が高速化を図れる。
高負荷のクエリーを分割
メモリー上で並列処理
同じ“In-Memory”という形容詞がついていても、「In-Memory Parallel Query」はOracle 11g R2の新機能である。TimesTen IMDBがアプリケーションサーバー側のメモリーを活用して高速OLTP処理を実現する技術とすれば、In-Memory Parallel QueryはDBサーバーが搭載するメモリーを使って検索処理の高速化を図る技術と位置づけることができる。
少し過去の経緯を説明しよう。Oracle製品で初めて並列処理を可能にしたのは、1990年代のOracle7である。データウエアハウスやバッチ処理など、負荷が大きい検索要求を高速で実行するために並列処理機能を持たせた。しかし当時のサーバーのCPUは32ビットが主流。搭載できるメモリー容量は小さく、メモリー上にデータをバッファしようとしてもすぐに溢れてしまう。そのため、従来の並列処理はディスクにアクセスする形態を採っていた。
しかし現在のサーバーは64ビットのマルチコアCPUが主流。メモリーも大容量化・低価格化が進み、2ソケットの小規模サーバーでも100GBを超える大容量のメモリーを搭載できる。こうしたハードウェアの進化を最大限に生かせるよう、Oracle 11g R2ではインメモリーで並列処理を実行できるようにした。それがIn-Memory Parallel Queryである。
この機能の特徴は、アプリケーションの開発者やデータベースの管理者が、特別な知識や技術を習得しなくていいことである。利用する場合、並列処理を実行する目安になる「しきい値」を設定すれば、必要な処理はOracle Databaseが自動的に行う。
例として、しきい値を10秒に設定したケースで考えてみよう。
アプリケーションサーバーからクエリーを受けるとOracle Databaseはまず、シリアル処理で何秒かかるか算出する(図4-2)。10秒を超えると判断したらプロセサや対象となる表(データ)、パーティションのサイズに基づいて、自動的に最適な並列度を決める。その上で並列度と同じ数のクエリースレーブを起動してメモリー内で並列処理を実行し、結果を集計する。
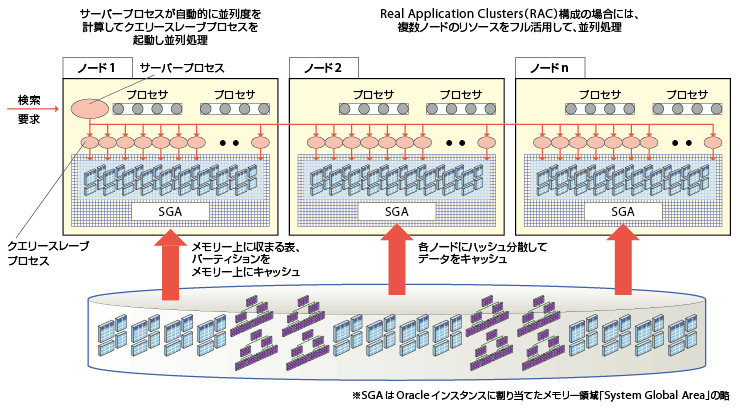
アプリケーションサーバーからのデータ検索要求を複数のプロセスに分割した「クエリースレーブプロセス」を作成し、 それぞれのクエリースレーブプロセスをクラスタを構成する複数のDBサーバーに分散。DBサーバーのメモリー上で高速に並列処理する
RAC構成の場合でも、基本は変わらない。使用可能なノードが搭載しているメモリー総容量とプロセサ総数によって、Oracle Databaseが並列度を判断する。対象となるデータを複数のノードに分散すればメモリーに乗せ切れる場合、データを各ノードにハッシュ分散。メモリー上にバッファした上で、RAC全体のプロセサを活用して並列処理を行う。
当然だが、メモリーに乗り切らない大きなデータは従来通り、ディスクにアクセスして並列処理を行う。また並列処理は一度に大量のリソースを使用するため、同時に複数の処理をすると、リソースの競合が発生しかねない。Oracle 11g R2では、並列処理の実行中でリソースに十分な余裕がない場合、別の並列処理を自動で待機させるようになっている。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
Oracle / Oracle Database / OLTP / RDBMS



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
