世界36カ所以上にデータセンターを持ち、クラウドコンピューティングサービスを展開するグーグル。 サービスを支える巨大なクラスタシステムを構成するサーバーは、数十万台とも100万台とも言われる。 過去に例がない大規模な並列処理を実現するため、グーグルは「MapReduce」と呼ぶ仕組みを自社で開発。 この仕組みを用いたデータ処理基盤として、ベンダーとユーザーの双方が注目する「Hadoop」の可能性を検証する。
※本記事はアイ・アイ・エム(IIM)発行の「IIMレポート」の記事に一部加筆・編集して掲載しています。
グーグルはクラスタシステムを活用するためのミドルウェアを自社開発している。分散型ファイルシステムを実現するGFS(Google File System)や分散型データベース機能を提供するBigTable、並列プログラムの実行を可能にするMapReduceについて、聞いたことがある読者も多いだろう。これらはクラスタシステムでの分散処理と並列処理を支えるだけでなく、高度な知識を持たないプログラマーでもプログラミングできるようにするなど、革新的なアプローチを採用している。
障害に強いソフトウェアが安いハードウェアを役立つものに変える─。グーグルはこうした“基本姿勢”を採っている。例えば、3年に1度しか故障しないサーバーでも1000台稼働させると、計算上は毎日1台が故障する。この問題に対処するため、グーグルは耐故障性を高める数多くの機能を自社開発したミドルウェアに組み込んだ。以下では、そのうちの1つ、並列プログラムの実行機能であるMapReduceについて詳しくみていく。
MapReduceとは、膨大なデータを短時間で処理することを目的としたプログラミングモデルだ。一般に、1つのプログラムを複数システムで並列実行させるには、プログラマーが並列処理を認識してプログラミングする必要がある。だが、MapReduceは並列処理に必要な機能をライブラリとして提供することで、並列処理の経験がないプログラマーでもプログラムを開発できるようにしている。
並列処理の手法(1)
入力・処理・出力で機能分割
本題に入る前に、並列処理の基本的な仕組みについて整理する。
システムの拡張性(Scalability)を確保する手法には、スケールアップとスケールアウトがある(図1)。業務処理で使用するCPU能力が不足した場合、前者は業務サーバーに搭載するCPU台数を増やし、後者は業務処理に使用するサーバーを新たに追加する。こうした違いこそあるが、いずれも並列処理を想定してプログラムを構成しておかなければ、基本的に新たに追加する資源(CPU能力)を活用できない点では共通している。
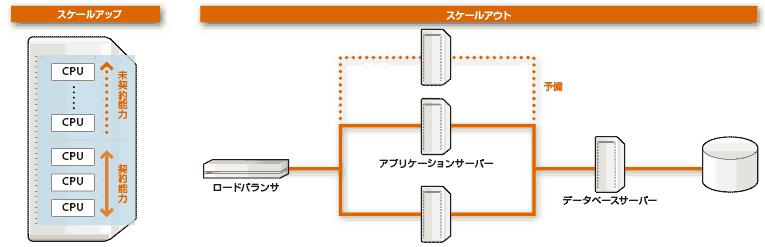
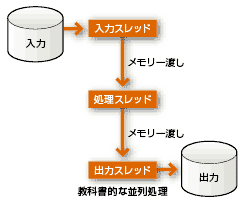 図2:並列処理プログラムの最もシンプルな構造。入力部、処理部、出力部の3つの機能をマルチスレッドでプログラミングする
図2:並列処理プログラムの最もシンプルな構造。入力部、処理部、出力部の3つの機能をマルチスレッドでプログラミングする並列処理を実現するプログラムの構造で最も簡単なのは、図2に示したように入力部と処理部、出力部の3つの機能をマルチスレッドでプログラミングするものだ。入力スレッドは入力レコードの読み込みに専念し、処理スレッドの実行速度にあわせて入力レコードの先読み操作を行う。処理スレッドは読み込まれたレコードの処理に専念し、出力データの書き込みは出力スレッドに任せる。こうして処理部でのCPU使用とI/O操作をオーバーラップさせて、一種の並列処理を実現する。
ただし、この構造は、言うなれば「教科書的」な並列処理プログラムであり、ごく限られた範囲のプログラムで使用できるテクニックである。
並列処理の手法(2)
ループ処理を複数タスクに分割
より実用的な並列処理プログラミング例の1つに、スーパーコンピュータにおけるプログラム実行形態がある。
我が国の代表的なスーパーコンピュータである地球シミュレータは、640台の計算ノードをクロスバ(ネットワーク)で結合している(図3)。1つの計算ノードは、毎秒8Gフロップスの演算能力を持つベクトルプロセサ8台と、16GBのメモリーで構成する。システム全体では5120台のベクトルプロセサによる40Tフロップスの演算能力と、10TBのメモリーを備える。個々の計算ノード間は毎秒約12GBの通信速度を持つネットワークで接続している。
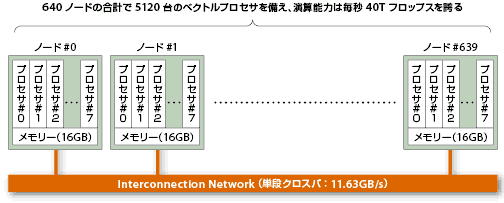
地球シミュレータのプログラム実行形態には3種類ある。1つは、Fortranなどで作成したベクトル計算プログラムを1台のベクトルプロセサで実行する方法だ。これは並列処理を考慮していない。
2つめは、計算ノードが備える複数(8台まで)のベクトルプロセサを活用するもの。Fortran90などのコンパイラが持つ自動並列化オプションを使えば、並列化を実現したコードを自動生成する。ループ文の処理はコンパイラが複数のマイクロタスクに分割する。このマイクロタスクはハードウェアの高速タスク間同期処理を活用した、並列処理のメカニズムそのものである。
そして3つめは、複数の計算ノードで1つの並列処理プログラムを実行させるものだ。Fortranなどで生成したコードを基にプログラムを分割し、MPI(Message Passing Interface)を使用して通信・同期・連携させる。2つめの実行形態と同様、プログラムソースを評価して自動的に並列化するコンパイラが重要な役割を果たす。
並列処理の手法(3)
複数プログラムにデータを分割
比較的に身近な並列処理のケースも紹介しておこう。FTPで膨大な量のデータが絶え間なく送られてくるシステムだ。こうしたシステムを運用している企業は少なくないだろう。
あるケースでは1本のプログラムでは、一定時間のうちに到底さばき切れなかった。そこでデータを分割し、同じプログラムを複数同時に実行することにした。処理データは日本全国からFTPで送られてくる。そこで地域ごとに集約する形で分割した。また、エラー発生時のリカバリー処理を容易にするために、1時間ごとに受信データを処理する。以上、説明は簡単だが克服すべき課題が多いことは想像に難くない。
課題を解決する際に考慮すべき重要なポイントが2つある。第1に、同時実行するプログラムの適切な本数をいかに求めるのかという点だ。
むやみに多くのプログラムを同時実行させると処理遅延が生じる。逆に少なすぎると所定の時間内に処理が完了しない。しかも、多重度の変更はデータ分割の方法(この場合なら地域分割)の変更を伴うため容易に踏み切れない。将来の処理データ量の増加を踏まえ、現行のデータ量を15分でさばける多重度をベンチマークを通じて求める必要がある。
第2のポイントは、エラー検出とリカバリー処理に関するものである。エラー発生時に人手でリカバリー処理をするには時間的に無理が生じる。そこでエラーの発生を自動検知し、再処理を自動スケジュールすることが欠かせない。スケジューリングの結果、リカバリー処理が本来予定されていた次の処理の時間に食い込む場合は、リカバリー処理が完了するまで後続の処理を待機させるようにする。
こうしたシステムは通常、ほとんどを手づくりしなければならない。
MapReduceで、経験が浅くても並列処理システムを開発可能に
グーグルのMapReduceやアパッチのHadoop(以下、MapReduceにはHadoopを含む)の並列処理の仕組みは、前述した3種の並列処理プログラムの構造のうちデータ分割に相当する。
MapReduceはLispなどの関数型記述言語をヒントとして開発されたもので、その名称にある通り「Map」と「Reduce」と呼ぶ2種類の機能で構成する(図4)。Mapは分割した入力データセットを構成するキーと値のペア(Key/Valueペア:以降、単にデータセットと呼ぶ)を並列処理し中間データを作成。ReduceはMapで作成した中間データを同じキーを持つデータ群としてマージして、出力データセットを作成する。

MapReduceを利用したプログラムを作ると、MapとReduceの機能を実行するプログラムコードがMapReduceのサーバー群にコピーされる。入力データセットの分割とMap機能への割り振りや、Map機能とReduce機能の関係、サーバー間通信、エラー検出とリカバリー処理などはMapReduceのライブラリ機能とMapReduceのデーモン(バックグラウンドで動作するプロセス)で管理・制御する。このようなプログラミングモデルを提供することで、並列処理プログラムの開発経験がないプログラマーであっても、簡単に大きな分散システムでの並列処理プログラムを開発できる。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- ERP導入企業は34.8%、経営改革や業績管理に活用する動きも─ERP研究推進フォーラム/IT Leaders共同調査(2013/02/07)
- ツールの効果的活用で機能品質高め─テスト工程のあり方を見つめ直す(2013/01/29)
- IaaSを利用する際、これだけは押さえておきたいセキュリティのツボ(2012/10/18)
- これからIT部門が育てるべき人材像とは(2012/08/24)
- ベテラン社員に技術やノウハウが偏在、情報システム部門の技能継承が課題に(2012/07/19)




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
