NTTデータは2016年6月21日、大量データを収集するためのOSS(Open Source Software)である「Fluentd(フルエントディ)」と「Embulk(エンバルク)」のサポートサービスを同日から開始すると発表した。そのため両ソフトウェアの開発元である米トレジャーデータの日本法人と連携し、単なる運用支援に留まらず、開発コミュテニティと連携しながらソフトウェア品質の向上や機能の向上につなげたい考え。
 図1:fluentdの新ロゴマーク
図1:fluentdの新ロゴマークNTTデータが開始したのは、ビッグデータの収集基盤となる「Fluentd(フルエントディ)」と「Embulk(エンバルク)」のサポートサービスである(図1)。Fluentdはリアルタイムでの、Embulkはバッチ処理でのデータ収集に対応したデータ収集基盤を構築するためのOSS。ビッグデータマネジメントのクラウドサービス「トレジャーデータサービス」を提供する米トレジャーデータが開発し、OSSとして公開した。
新サービスは、既に提供している大量データの分析基盤である「Hadoop」およびリアルタイム処理に対応した「Spark」のサポートサービスを拡充する形で提供する(図1)。Fluentd/Embulkを使うシステムの設計・開発および運用・保守のフェーズにおいて、導入・設定方法やソフトウェア仕様の確認、不具合の解析と 回避策といったサービスをNTTデータが提供。それをトレジャーデータがソースコードレベルの解析や必要なパッチの作成などで後方支援する。
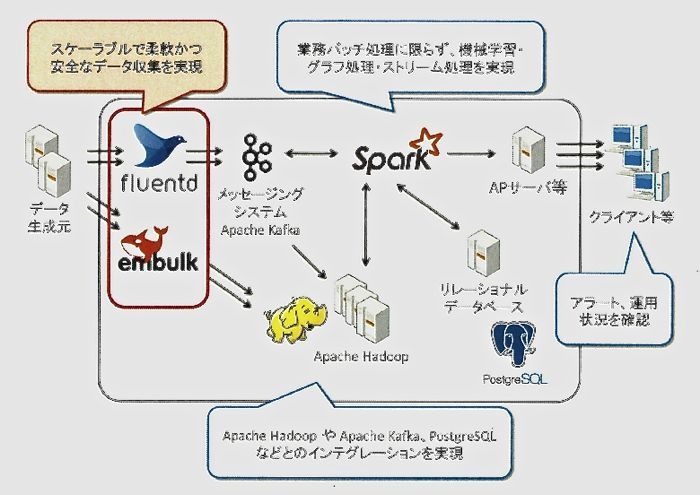 図1:Hadoop/Sparkによるデータ分析システムにおけるFluentd/Embulkの位置付け(出所:米トレジャーデータ)
図1:Hadoop/Sparkによるデータ分析システムにおけるFluentd/Embulkの位置付け(出所:米トレジャーデータ)拡大画像表示
これまでNTTデータでは、既存システムからのデータ受け渡しなどはシステムごと個別に対応してきた。開発期間やコストの削減に向け、データ収集を容易にするツールとしてのFluentd/Embulkのサポートを求める声が高まってきたことに対応する。NTTデータは今後、サポートサービスを通じてノウハウを蓄積しながら、Fluentd/Embulkの構築サービスにも乗り出す考えである。
Fluentd/Embulkの導入においては、日本市場では個別企業がオンプレミスに導入するケースが先行。これに対し米国市場ではログ収集のOSSとしての認知が高まりつつあるという。例えば、米Microsoftはハイブリッドクラウド環境を管理するためのクラウドサービス「Operations Management Suite」におけるログコレクターにFluentdを採用している。
NTTデータによれば、Hadoop/Sparkを使ったシステム構築は、通信事業者やゲーム、マーケティング分野などで先行してきたものが、昨今は金融機関や製造業における事例も増えている。今後はIoT(Internet of Things:モノのインターネット)関連ニーズの高まりから収集・分析対象になるデータの多様化/大量化が起こるとみられ、Fluentd/Embulkは「対象にするデータ形式に併せて収集機能をモジュール型で切り替えられるため、IoT関連ニーズにも応えやすい」(NTTデータ)としている。


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
