[新製品・サービス]
インフォア、セルフサービスBIと全社アナリティクスを提供する「Infor Birst」を国内リリース
2019年4月24日(水)五味 明子(ITジャーナリスト/IT Leaders編集委員)
米インフォア(Infor)の日本法人インフォアジャパンは2019年4月12日、クラウドネイティブなBIプラットフォーム「Birst」の国内提供を開始した。単体の製品としてだけではなく、クラウドERP「Infor CloudSuite」のオプションとしても提供される。同社としてはBurstの投入で、国内ビジネス/ポートフォリオのクラウドシフトをさらに推し進めたい意図もある。
インフォアジャパンは現在、国内市場でのクラウドビジネスの比率を「3年間で40%まで高める」(同社 副社長執行役員 営業本部長 三浦信哉氏/写真1)ことを目標にしている。今回、クラウドネイティブなBI/アナリティクスプラットフォームの「Birst」(図1)を投入することで、その戦略をより強化していく方針だ。
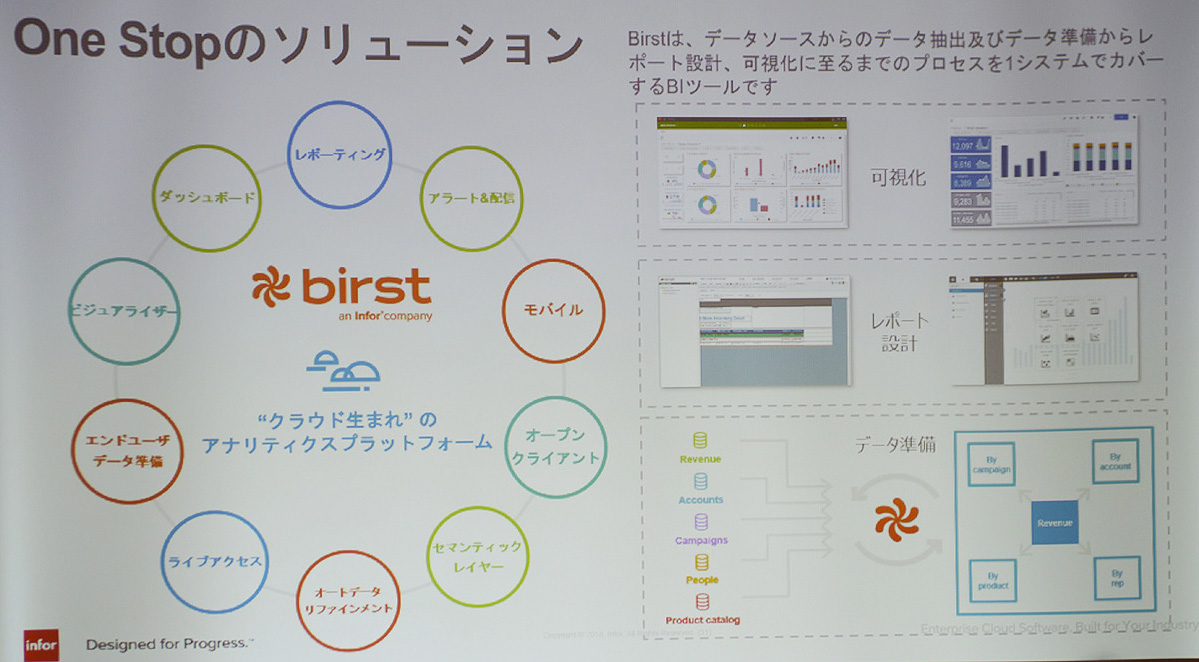 図1:Birstは、データの集約から可視化までをワンストップで提供するクラウドネイティブなBIツールである(出典:インフォアジャパン)
図1:Birstは、データの集約から可視化までをワンストップで提供するクラウドネイティブなBIツールである(出典:インフォアジャパン)拡大画像表示
セルフサービスBIと全社アナリティクスを提供する「ネットワークBI」
 写真1:インフォアジャパン 副社長執行役員 営業本部長 三浦信哉氏
写真1:インフォアジャパン 副社長執行役員 営業本部長 三浦信哉氏Birstはマルチテナントのクラウドアーキテクチャ(AWS)上に構築されるBIプラットフォームだが、対象のデータソースはパブリッククラウドに限らず、プライベートクラウドやオンプレミスにも対応する。
最大の特徴は組織ごと、あるいはデータソースごとに分析準備を整えたデータをクラウド上で共有する「ネットワークBI」だ。この機能により、部門単位のセルフサービスBIと、全社横断のエンドツーエンドなアナリティクスの両方を実現することが可能になる(図2)。
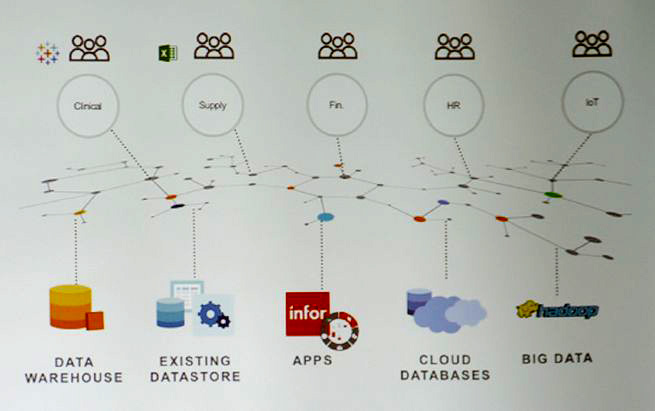 図2:Birstの最大の特徴である「ネットワークBI」は、部門ごとやデータソースごとに準備したデータをクラウド上で共有する仕組み。統一されたルールの下で集約されているので、正確性が担保され、組織をまたいだ分析もしやすくなる
図2:Birstの最大の特徴である「ネットワークBI」は、部門ごとやデータソースごとに準備したデータをクラウド上で共有する仕組み。統一されたルールの下で集約されているので、正確性が担保され、組織をまたいだ分析もしやすくなる拡大画像表示
生データではなく、部門ごとに適切に管理された準備済みのデータを共有することで、データの重複管理やKPIの一貫性保持が可能になり、データ分析の正確性を担保しやすくなる。
例えば、「利益(profit)」という用語を、部門Aは「収益(revenue)-コスト(cost)」と定義しているが、部門Bでは「収益-コスト-値引き(discounts)」という意味で用いており、さらに部門Cでは「収益-コスト-運用益(return)」を利益としている会社があるとする。この場合、もし、各部門の用語ルールを統一せずに「利益」に関連するデータを集約し分析を実施すれば、当然ながら分析結果の正確性を担保することは難しくなる。
Birstでは、セマンティックレイヤ(Semantic Layer)モデルでこの問題の解決を図っている。同モデルを使って、あらかじめ全データソース/全組織にわたって分析に必要なデータの属性、グルーピング、メジャー、セキュリティレベルなどを管理し、アナリティクスの正確性やガバナンスを担保するという仕組みだ。
前述の「利益」の例で言えば、例えば、「収益-コスト-ディスカウント"を全社共通の「利益」としてルール化した場合、各部門の「利益」データはすべてそのルールに従って自動で整形された後にクラウドに集約される。さらに、複数のデータソースからメタデータを解析し、分析に必要なデータモデルを自動で作成する「オートリファイン」機能により、担当者はETL(Extract/Transform/Load)など特別なツールを入手したり、IT部門にデータフィードの提供を依頼したりする必要はない。
 写真2:インフォアジャパン ソリューションコンサルティング本部 本部長 石田雅久氏
写真2:インフォアジャパン ソリューションコンサルティング本部 本部長 石田雅久氏また、インテリジェントなクエリエンジンやマルチティア型キャッシュ構造、カラムナ(Columnar:列指向)データベースとインメモリデータベースの併用など、パフォーマンスやスケーラビリティに関しても「エンタープライズの利用に耐えうるレベル」(インフォアジャパン ソリューションコンサルティング本部 本部長 石田雅久氏/写真2)のBIプラットフォームに仕上がっているという。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
Infor / アナリティクス / セルフサービスBI / CloudSuite


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
