近年、多くの企業がAIやビックデータの活用に積極的に取り組んでいるが、AIや機械学習から有益な知見を獲得するためにはデータの収集段階から正しいステップを踏み、膨大かつ多様なデータを適切に分析する必要がある。同時にセキュリティや法令遵守を維持しながら、異なる組織やチーム間で連携することも不可欠だ。「データマネジメント2020」のセッションでは、Databricks Japanの岡本智史氏が登壇。DatabricksがAI/機械学習の推進に向けて提供する統合型データアナリティクスプラットフォームの優位性と、同プラットフォームを活用した世界のリーディングカンパニーによる成功事例が紹介された。
「機械学習」にたどり着くまでの困難さ
ビッグデータを扱うための基盤環境であり、“ポストHadoop”とも呼ばれるApache Spark。その生みの親であるマテイ・ザハリア氏と共に、アリ・ゴディシ氏が2013年に共同設立した企業がDatabricksだ。同社の主力ビジネスはAI/機械学習のための統合プラットフォームの提供にあり、世界で2000社以上のユーザーを擁するほか、テクノロジー販売パートナーも450社以上に到達。データサイエンスと機械学習の領域で急成長を遂げたユニコーン企業として、市場から高い評価を獲得している。
 Databricks Japan株式会社 マーケティング マーケティング・ダイレクター 岡本智史氏
Databricks Japan株式会社 マーケティング マーケティング・ダイレクター 岡本智史氏近年、「計算能力の大幅な向上」「学習データの増大」「クラウドのコスト低下」を背景に企業におけるAIの活用が急速に進んでいる。また、そうしたAI/アナリティクスの潜在価値は、すべての産業において、約950~1540兆円もの経済的な価値を生む可能性があるとの報告も寄せられている。
「企業のAI/機械学習に対する期待は非常にシンプルである。それはデータを収集して機械学習を行い、ビジネスに有効なインテリジェンスを導き出すことで、コスト削減や生産性向上、そしてイノベーションを実現したいというものだ。しかし、実際に機械学習に辿りつくまでには設定からデータの収集、データの正当性の確認、分析ツールやインフラの準備、モニタリングまで、膨大なタスクをこなしていかなければならない」と岡本智史氏(同社マーケティング・ダイレクター)は訴える。
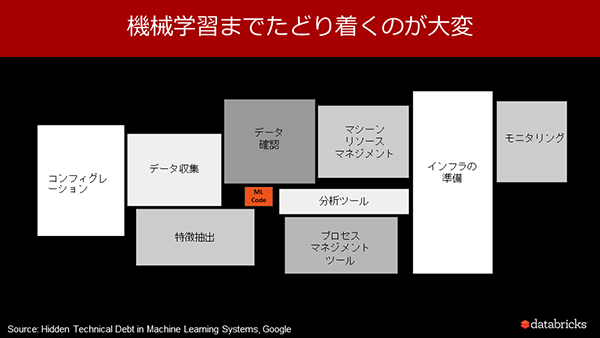 機械学習にたどり着くまで膨大なタスクをこなしていかなければならない
機械学習にたどり着くまで膨大なタスクをこなしていかなければならないAI/機械学習の推進を阻害する4つの課題とは
同氏によれば、そうした膨大なタスクが以下に挙げる4つの課題を生じさせているという。
① データの肥大化、サイロ化
データはリアルタイムで収集されるものもあれば、定期的に集められるものもある。またその種類もWebアクセスログ、顧客情報、価格/原材料情報、ロジスティクス、RNA/ゲノム情報など非常に多岐にわたる。これまで企業は、こうしたデータの収集頻度や種類に合わせてデータ格納基盤を構築していたため、昨今のデジタル化に伴うデータの肥大化と共に、サイロ化が大きな課題となっている。
② 複雑な機械学習のサイクル
一般に、データエンジニアは様々な種類のデータを収集した後、機械学習可能なデータセットの準備、フォーマットに変換、それを用いてデータサイエンティストが分析を行う。しかし、スキルセットや求められる知識は両者では異なり、コラボレーションがうまくいっていないケースも少なくない。また、データサイエンティストは多様な機械学習モデルを幾度となくテストを行い、頻繁にデータセットに変更が生じるため、その都度データエンジニアにデータセットの依頼をする必要がある。これが全体の機械学習のライフサイクルの生産性低下につながってしまっている。
③ BIツールの限定的な可視性
特定のBIツールが限られたデータセットにしかアクセスすることができず、その結果、不十分な分析により、偏ったアウトプットや、全体像にかける知見しか得られない、という課題が発生している。また、複数のデータソースへのアクセスが必要とわかっていても、システムレベルでの連携が難しいため、諦めているというケースも少なくない。
④ エンタープライズレベルのシステム性の欠如
実際の運用に耐えうるようなセキュリティの確保やインフラの信頼性、ガバナンスの担保といった、企業の必要要件を満たすことが困難となっている。特に、これまでオンプレ環境で機械学習を行っている場合は、これが顕著であり、先に述べたデータのサイロ化に伴い、セキュリティレベルも各システムでバラバラになってしまっている。
企業のAI/機械学習に関する課題をトータルで解決するプラットフォームを提供
「これらの課題を統合的に解決するものが、Databricksの統合型データアナリティクスプラットフォームだ」と岡本氏は強調する。
プラットフォームを支えるインフラにはエンタープライズでの運用に耐えうるAWSやMicrosoft Azureのクラウド基盤を採用し、その上位層では統合化されたデータサービスを実現するためのSparkを活用した高速エンジンおよび多種多様なデータを格納可能なDelta Lakeを配備した。そして最上位層には、機械学習のライフサイクルを容易に管理可能とするためのMLflowをはじめ、機械学習のためのライブラリであるTensorFlow、PyTorch、scikit-learnなど、データサイエンスのためのワークスペースを用意した。
さらに、TablueやQlik、Lookerといった主要なBIツールも統合したことで、Delta Lakeに保存されている全てのデータソースに直接アクセスすることを可能としている。
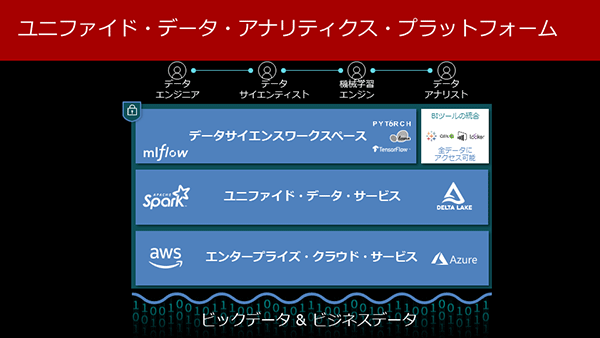 Databricksの統合型データアナリティクスプラットフォーム
Databricksの統合型データアナリティクスプラットフォーム「例えば、肥大化/サイロ化の問題であるが、Delta Lakeにより非構造化、構造化、半構造化データも全て一括して格納することを可能としている。また、データサイエンティストとデータエンジニアの共同作業についてもコラボレーションをより容易にするツールを提供。例えば、事前に要件を設定してデータサイエンティストが作成したモデルを自動的にプロダクションに移行したり、モデルの変更履歴を一覧で参照したりすることも可能だ。BIツールの限定的な可視性の問題では、主要なBIツールを統合したことで、Delta Lakeに格納された多種多様なデータにダイレクトにアクセスできるようになっている」(岡本氏)。
また、エンタープライズレベルのシステム性の欠如についても、AWSやAzureの堅牢なクラウド基盤との統合を行うことで、企業ごとに対応するよりも、はるかに安全なアクセス管理や、データマネジメントを実現している。こうした堅牢なクラウド基盤を活用することで、GDPRや個人情報保護法、法対応についても柔軟かつ迅速な対処が可能となっている。
Databricksの採用で、約9億円のコストを削減し、データサイエンスの生産性を30%向上
続いて岡本氏は、Databricksの統合型データアナリティクスプラットフォームを活用した世界各国の企業の成功事例を紹介した。
はじめに紹介されたのが、世界最大級のメガバンクであるHSBCのユースケースである。同銀行では、パーソナライズされたモバイルバンキングを提供するため、機械学習を活用した顧客向け製品の開発基盤の強化を進めている。そのための基盤としてDatabricksを採用した理由は、データサイエンス、データエンジニア、BIのすべてを1つのプラットフォーム上に統合できることと、従来、異なる基盤で収集されていたリアルタイムデータとバッチデータの統合処理を可能とすることにあった。最終的に同銀行では、Databricksの活用により、モバイルアプリの使用率を4.5倍に増加させたほか、データプロセスも6時間から6秒へ短縮、そして14以上のデータベースを1つに集約させたことで大幅な生産性の向上を実現できたという。
また、アメリカのケーブルテレビ/エンタテインメント大手企業であるComcastは、Databricksを採用し、視聴者に提供された2000万機以上にもおよぶ音声入力対応のリモートコントローラーからの音声リクエスト処理に機械学習を適応。パフォーマンスの大幅な向上により、計算リソースを10分の1に削減したほか、100名以上のデータサイエンティストがリアルタイムに協調可能な基盤を構築。さらにモデル展開のリードタイムも数週間から5分へ短縮させることができたという。この結果、約9億円のコスト削減とデータサイエンスの生産性が30%向上する結果となった。
このほかにも岡本氏からはDatabricksの導入により、数々の成果をもたらしたグローバル企業の成功事例が語られた。
セッションの最後に岡本氏は「Databricksはお客様の職種に応じてカスタマイズしたワークショップを無料で開催している。その対象もビジネスユーザーをはじめ、データを加工分析、収集するデータエンジニア、モデルを作成するデータサイエンティスト、BIユーザーまでを包含している。ぜひ一度、お問い合わせ頂きたい」と述べ、講演を締めくくった。
●お問い合わせ先

Databricks Japan株式会社
TEL:03-6821-1670
Email:sales-jp@databricks.com
URL: https://databricks.com/jp/
- サイロ化された業務体系が阻害要因に~DX時代の競争優位を導くMDMの成功要因とは?(2021/01/25)
- データの価値を最大化する戦略アプローチと、データドリブン文化の醸成に向けて(2020/05/27)
- 社内データの意味を見える化し全方位から把握! ビッグデータ活用は“メタデータマネジメント”が鍵に(2020/04/21)
- アジャイルなデータ統合・活用を実現するデータ仮想化技術の最前線(2020/04/17)
- 真のデータ駆動型の組織を実現する持続可能なデータ統合のフレームワークとは(2020/04/15)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
