Preferred Networks(PFN)は2021年6月14日、神戸大学と共同開発した深層学習用プロセッサ「MN-Core」専用コンパイラを開発したと発表した。深層学習における複数の実用的なワークロードの計算速度を、最大で従来の6倍以上に高速化した。
[訂正のお知らせ]Preferred Networksが行ったニュースリリースの訂正に基づき、本記事におけるMN-Coreの性能評価プログラムに関する記述を訂正しました。(2021/06/23 11:30)
誤:インスタンスセグメンテーションで6倍以上
正:画像認識で6倍以上
Preferred Networks(PFN)の「MN-Core」は、ディープラーニング(深層学習)の学習工程を高速化する用途に特化したプロセッサである(関連記事:PFN、深層学習プロセッサ「MN-Core」を発表、2020年春に2EFLOPSの大規模クラスタを構築、写真1)。行列演算器を高密度に実装し、条件分岐がない完全SIMD動作をするシンプルなアーキテクチャを採用し、チップあたりのピーク性能は、深層学習で頻用する半精度浮動小数点演算で524TFLOPS(テラフロップス、1秒あたり524兆回)である。
 写真1:MN-Coreの外観(出典:Preferred Networks)
写真1:MN-Coreの外観(出典:Preferred Networks) PFNは今回、深層学習のフレームワークであるPyTorchからMN-Coreを利用するための専用コンパイラを開発した。これを用いてコンパイルすることで、開発済みの既存のアプリケーションに大きな変更を加えることなく、MN-Coreを利用して計算を高速化できる。このコンパイラでコンパイルしたアプリケーションの実行速度を、汎用GPUを搭載したPFNのスーパーコンピュータ「MN-2」と比較したところ、画像認識で6倍以上、グラフ処理で約3倍の高速化を達成した(図1)。
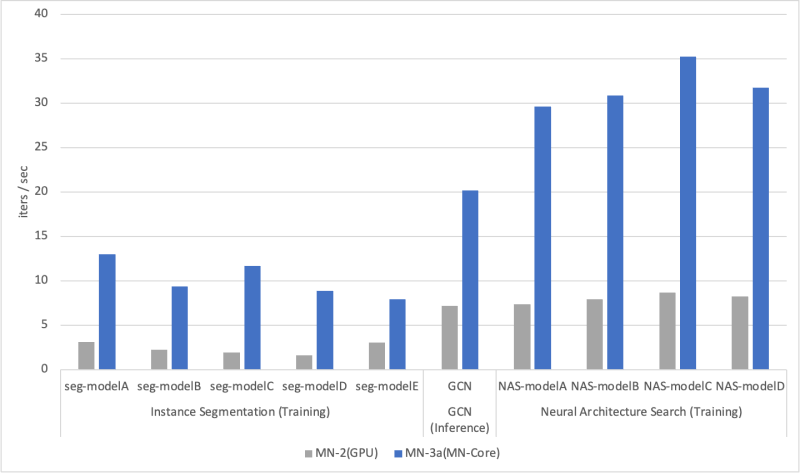 図1:深層学習ワークロードにおけるMN-2とMN-3(MN-Core)の単位時間あたりの処理性能比較(出典:Preferred Networks)
図1:深層学習ワークロードにおけるMN-2とMN-3(MN-Core)の単位時間あたりの処理性能比較(出典:Preferred Networks)拡大画像表示
PFNのスーパーコンピュータ「MN-3」がMN-Coreを搭載している。MN-3は、TOP500リストのLINPACK性能を消費電力で割り、1ワットあたりの性能を比較したGreen500リストにおいて、2020年6月に1位を記録している(関連記事:Preferred Networksのスパコン「MN-3」が電力当たり性能の「Green500」で歴代1位に)。
PFNは、2020年5月にMN-3の試験稼働を開始して以来、深層学習をより高速化するためのソフトウェア群の開発を続けてきた。今回の専用コンパイラは、こうした活動の成果であるという。
Preferred Networks / MN-Core / コンパイラ / ディープラーニング / HPC

- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
