国立情報学研究所(NII)の大規模言語モデル研究開発センターは、日本語に強い大規模言語モデル(LLM)の研究開発を進めている。2025年3月7日に開催された「データマネジメント2025」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)の基調講演に登壇したNII所長/大規模言語モデル研究開発センター長の黒橋禎夫氏は、LLMの歴史を解説すると共に、LLM-jpによる日本語LLM開発の取り組みを紹介した。
 写真1:国立情報学研究所(NII) 所長/大規模言語モデル研究開発センター長の黒橋禎夫氏
写真1:国立情報学研究所(NII) 所長/大規模言語モデル研究開発センター長の黒橋禎夫氏拡大画像表示
国立情報学研究所(NII)の大規模言語モデル研究開発センターと、言語モデルの研究者を集めたLLM勉強会(LLM-jp)では、日本語に強い大規模言語モデル(LLM)の研究開発を進めている。
NII所長/大規模言語モデル研究開発センター長の黒橋禎夫氏(写真1)は「データマネジメント2025」の基調講演で、LLMの歴史を解説すると共に、LLM-jpによる日本語LLM開発の取り組みを紹介した。
講演の前半では、LLMの歴史を解説した。LLMは推論時、入力に対してニューラルネットワークが次の単語を推測する。言語モデルの歴史は長く、最初はコーパス(言語資料)内に出てくる単語の個数を判断材料として、次に来る単語を予測していた(図1)。例えば、「私はりんごを」の次に来る確率が高い(回数が多い)単語として「食べた」という正解を出していた。
 図1:初期の言語モデルは、コーパス(言語資料)内にある単語の出現回数を判断材料として、次に来る単語を予測していた(出典:国立情報学研究所)
図1:初期の言語モデルは、コーパス(言語資料)内にある単語の出現回数を判断材料として、次に来る単語を予測していた(出典:国立情報学研究所)拡大画像表示
その後、意味をベクトルで表現するようになった(図2)。意味が似ている語句は、類似のベクトルになる。リンゴとアップルなど、異なる言語の単語同士でも、意味が近ければ同じ方向のベクトルになる。「1次元の情報が-1/1の2つでも、1000次元あれば2の1000乗(およそ10の30乗と同じ)になり、非常に大きな世界を表現できる」(黒橋氏)。
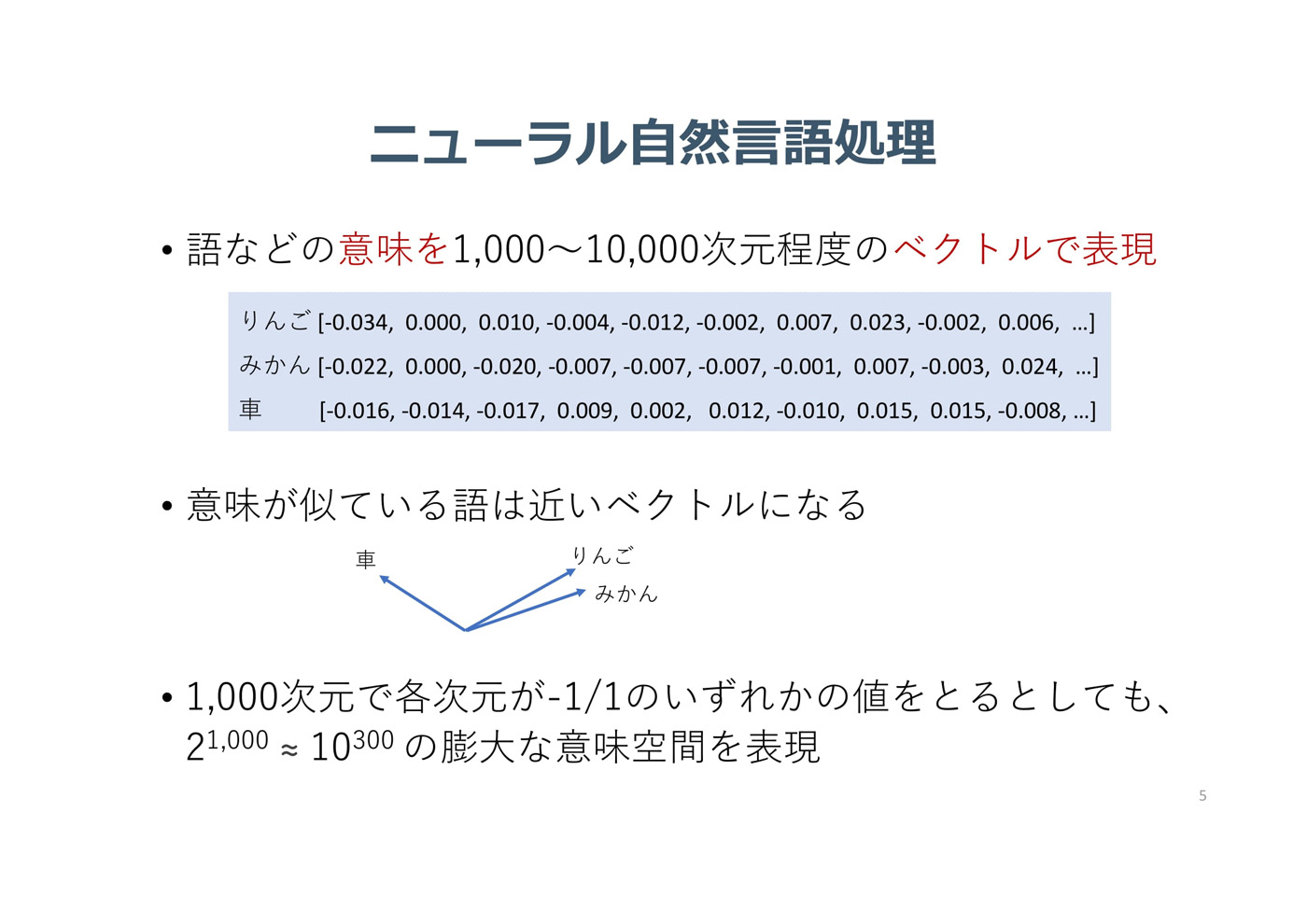 図2:語などの意味をベクトル化(数値化)したデータを作っておくことにより、近いベクトルを探すことで意味が似た語句を抽出できるようにした(出典:国立情報学研究所)
図2:語などの意味をベクトル化(数値化)したデータを作っておくことにより、近いベクトルを探すことで意味が似た語句を抽出できるようにした(出典:国立情報学研究所)拡大画像表示
入力層、中間層、出力層という基本的な順伝播型のニューラルネットワークを再帰型(回帰型)に展開したRNN(リカレントニューラルネットワーク)によって、連続した情報や時系列の情報を扱えるようになった。順番に入ってきたデータに対し、順番に何かを予測する形である。これは最初、翻訳に使われた(図3)。その後、RNNの進化系/後継として、2014年にAttention(入力データから重要な部分を抽出する機構)、2017年にはTransformerモデルが登場した。
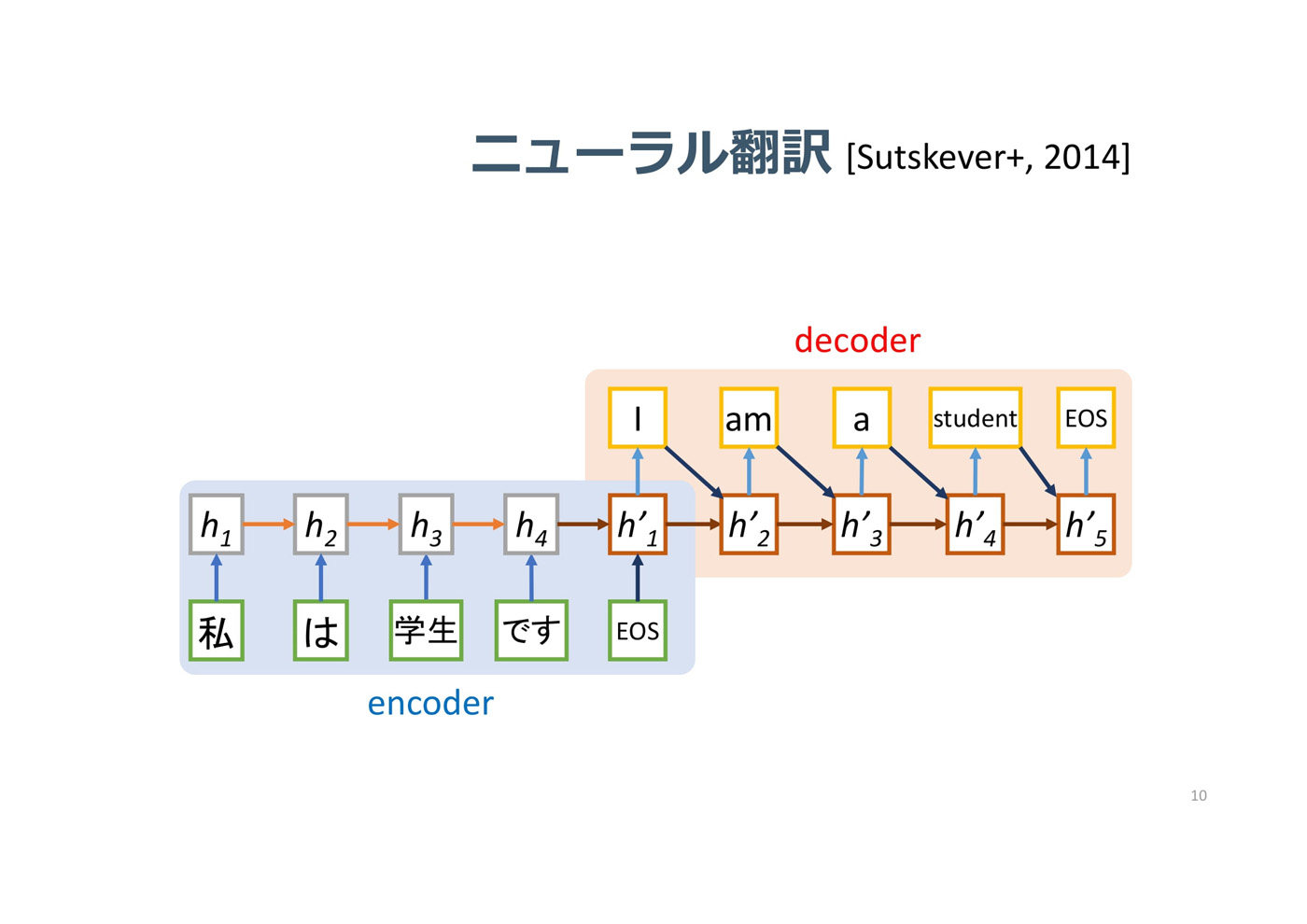 図3:再帰型(回帰型)のRNN(リカレントニューラルネットワーク)により、連続した情報や時系列の情報を扱えるようになった。これは最初、翻訳に使われた(出典:国立情報学研究所)
図3:再帰型(回帰型)のRNN(リカレントニューラルネットワーク)により、連続した情報や時系列の情報を扱えるようになった。これは最初、翻訳に使われた(出典:国立情報学研究所)拡大画像表示
LLMは登場以来、パラメータ数が急増している。1つの到達点として、2020年には1750億パラメータを持つOpenAIの「GPT-3」(175B)が登場した。また、パラメータ数のほかにも、「質問と回答のデータセットなどのインストラクションデータによるファインチューニングなどがLLMの性能の向上に重要」と黒橋氏は指摘する。また、強化学習を利用し、複数の出力から適切なものを人間に選ばせ、人間が選んだものをより多く出力するといったチューニングも有効である。
マルチモーダル化も重要な進化である。「GPT-4」では言語だけでなく、画像も理解するようになった。肺のCT画像を見て診断したり、図を含んだ物理学の問題を解いたりするようになった。
●Next:LLM勉強会による日本語LLMの開発状況
会員登録(無料)が必要です




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
