[市場動向]
富士通、1ビット量子化でLLMを軽量化、精度を89%維持してメモリー消費を94%減
2025年9月8日(月)日川 佳三(IT Leaders編集部)
富士通は2025年9月8日、大規模言語モデル(LLM)軽量化のための、計算精度を1ビットまで粗くしても計算精度を高く維持する技術を開発したと発表した。軽量化前と比べて89%の精度を維持しつつ、推論時のメモリー消費量を94%削減するという。ハイエンドGPU4個をローエンドGPU1個で代替できるとしている。同技術を適用した同社製LLM「Takane」のトライアル環境を2025年度下期から提供する。
富士通は、大規模言語モデル(LLM)軽量化のための、計算精度を1ビットまで粗くしても計算精度を高く維持する技術を開発した。
軽量化前と比べて89%の精度を維持しつつ、推論時のメモリー消費量を94%削減するという。この技術を同社のLLM「Takane」に適用する。ハイエンドGPU4個をローエンドGPU1個で代替できるとしている。
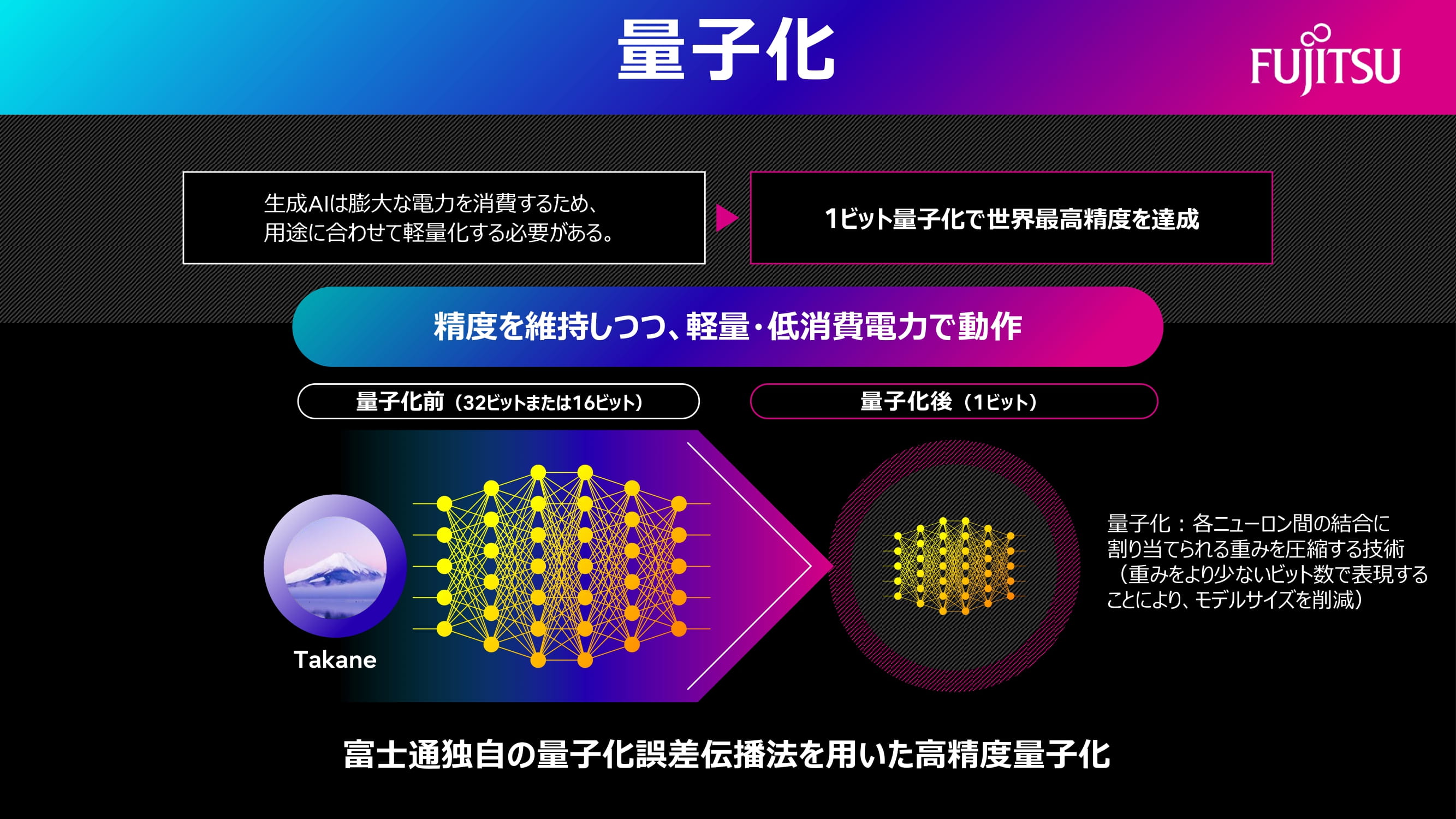 図1:ビット数(計算精度)を粗くして軽量化する量子化の概要(出典:富士通)
図1:ビット数(計算精度)を粗くして軽量化する量子化の概要(出典:富士通)拡大画像表示
LLM軽量化の方法に、計算精度であるビット数を粗くして軽量化する量子化をとった(図1)。「一般に、AI向けには精度が低めの半精度(16ビット)や8ビットの演算を使うことが多いが、今回採用した1ビット(2値)は、ビット表現としては最も低いものになる」(富士通)。
1ビット量子化でも精度を維持する工夫として、層をまたがって量子化の誤差が蓄積されないように、誤差を補正して伝播させるアルゴリズム「QEP(Quantization Error Propagation:量子化エラー伝搬)」を新たに開発した(図2)。「従来手法では、LLMのような層が多いニューラルネットワークにおいて、量子化誤差が指数関数的に蓄積することが課題だった」(同社)。
 図2:富士通が開発した量子化アルゴリズム「QEP(量子化エラー伝搬)」の概要(出典:富士通)
図2:富士通が開発した量子化アルゴリズム「QEP(量子化エラー伝搬)」の概要(出典:富士通)拡大画像表示
1ビット量子化に従来の主流手法(GPTQ)を適用した場合と、今回のQEPとの差をベンチマークを行って比較している(図3)。FP16(16ビット浮動小数点演算)がINT1(1ビット整数演算)になることでメモリー使用量が94%減となる点は共通だが、出力精度は従来手法の10%に対して今回開発したQEPは89%を維持している。
 図3:従来の一般的な量子化アルゴリズム「GPTQ」と富士通が開発した「QEP」の出力精度を比較した試験の結果(出典:富士通)
図3:従来の一般的な量子化アルゴリズム「GPTQ」と富士通が開発した「QEP」の出力精度を比較した試験の結果(出典:富士通)拡大画像表示
富士通は合わせて、専門知識を凝縮して精度を向上させる特化型のAI蒸留技術(注1)を開発している。今回、特定のユースケースに特化した知識のみで専用モデルを再構築することで、教師モデルを超える精度を、より軽量な100分の1のパラメータサイズの生徒モデルで達成できることを確認したという。
注1:AIモデル開発における蒸留(Distillation)とは、LLMなど大規模な基盤モデルが蓄積したナレッジを教師に、軽量なモデルに継承させる技術のこと。大規模モデルの持つ高い精度や汎用性を維持しつつ、モデルサイズを小さくすることで、推論に必要な計算リソースの削減、コンパクトゆえの高速な推論、エッジデバイスで動作可能な省電力などの利点がある。
富士通は、今回開発した技術を適用したTakaneのトライアル環境を、2025年度下期から提供する。ほかにも、カナダCohereの研究用LLM「Command A」を同技術によって量子化したモデルをHugging Faceで2025年9月8日から公開する(関連記事:富士通、日本語能力を高めたLLM「Takane」を提供開始、業種特化のカスタマイズが可能)。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
