不明確なデータ入力ルールが、システムの活用を阻害する:第2回
2010年8月4日(水)大西 浩史(NTTデータ バリュー・エンジニア 代表取締役社長)
情報システムを経営に生かす-その根源となるのはデータの品質である。SOA(サービス指向アーキテクチャ)やクラウドコンピューティングなど技術革新の激しいITの世界だが、データ品質の維持管理の視点が欠けていては恩恵を享受することはできない。「活用されるシステム」を具現化するための、データマネジメントの勘所を解説する。
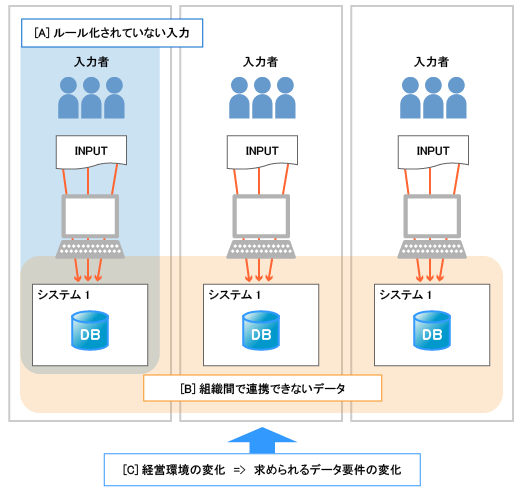
今回は、同一システム内でデータ入力の基準やチェック観点・体制等の運用ルールが定まっていないことに起因するデータ品質の問題と、その対応策を説明する。([node:2307,title="前回"]説明した3つの問題のうち、図1のAの部分)
「名寄せ(なよせ)」という言葉を耳にしたことがあるかもしれない。例えば、結婚して姓が変わってしまった場合でも、旧姓と新姓の人は別人ではなく、名前、住所、電話番号等の他の属性との相関から判断して同一人物であることを示すため、新旧の姓、2つのデータを紐づける処理が、名寄せの端的な例である。
公的年金の未払い問題では、結婚や転職を繰り返す中で、年金受給権者のデータが分散、欠落、さらに記載上の誤りが生じ、名寄せの必要性がクローズアップされている。
「コンピュータを使えば、そうした情報をすばやく見つけ出して、関連付けられるのではないか」と思われるかもしれない。
確かに、氏名・社名、住所、電話番号などを検索時の手がかりにして、ある程度の名寄せ処理を自動化できるツールは多々あるが、事態はそう簡単には解決されない。データの類似性、相関関係から「そのデータが同じ人か違う人か」を判定するときの基準やルールをどう設定するかというのが厄介な問題の一例だ。また、「一定期間の記録が存在しない」等の“データ欠落”の問題、意図的かどうかを問わず入力されたデータの値の“意味不明”の問題(例えば、申込書上「生年月日」が判読できなかったので、ダミーの「99999999」が入っている等)など、問題は多く存在する。皆さんも自社内で使っているシステムの中のデータを思い浮かべたら、多くの方は「名寄せツールを導入したらそれで問題解決」とはならないことが容易に想像つくだろう。今回は、購買履歴データを使ったわかりやすい具体的な事例で、データ品質が経営改善に大きなインパクトを持ち得ることを説明したい。
“データ無法状態”となっている購買履歴データ
図2をご覧いただきたい。これは、とある業界の最大手優良企業における物品を調達した際の購買履歴データである。一見、さまざまな種類、価格のパソコンをさまざまな取引先から購入しているように見える。
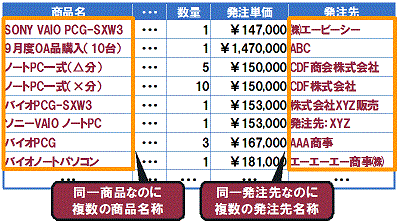
図2 大手企業における購買履歴データの例
たとえば、「ノートパソコン一式」とシステム上入力されると、後からそのデータを見たときには「一体、どのメーカ、品番のノートパソコンをどのくらいの値引率で購入したか」が全く不明になってしまう。データとは、担当者のデータの入れ方によって、いとも簡単に「ものごとの実像」を現さない存在になってしまうことを認識しなければならない。
なお、上から2行目の発注単価の欄には、「\1,470,000」とあるが、数量の欄を見ると「1」になっているにもかかわらず、商品名を見ると「(10台)」と書いてあり、まとめ買いの合計金額であることが分かる。単価と見誤ってしまう可能性が高い記述の仕方だ。しかし、このように記述されていても、システムでは見分けることができず、これを単純に「1台の値段は、\1,470,000」と認識して処理を行う。上記の表のように、属性や値に「ユレ」のあるデータを用いて集計・分析を行ったところで、正しい結果は到底得られないのである。
なぜ、“データ無法状態”が放置されるのか
問題が根深いのは、データを入力する人と、そのデータを活用する人の利害が必ずしも一致しないケースが多いという点だ。
物品を発注する側の担当者と受注する営業マンの間で、紙の見積書やExcelなどで「何がほしいか」が特定されていれば、「パソコン一式」という表現や極端に言えば「例のブツ」という品名でオーダーされたとしても、営業マンは「ああ、あの時見積もった物件の注文が来た」と属人的な判断で受注・納品処理に回せる。そのため、個々の発注処理上は何の支障もない。発注担当者も自分がオーダーした物品が指定した納期・数量どおりに手元に届けば何の問題もないのである。
ひるがえって、購買履歴データをコストダウン活動に活かしたい調達・購買部門としては、このように乱雑に入れられた無法状態のデータを眼前にして、どうやってサプライヤーとのボリュームディスカウントや単価交渉の材料としていけばよいのか……。「活用したい」を考えた途端、途方にくれるのである。
紙の見積書を集め、良質なデータを再構築
この企業でも現状のデータの問題を何とか打開しようと、大手ベンダーのBIツール導入や取引先名称の名寄せツールの購入などの投資を行い、さまざまな対処策を模索してきた。しかし、システム的な対処だけでは必要十分な解決策にならず、購買履歴データの正しい分析はずっと行えない状態にあった。
こうした場合、対策は2つの道しかない。データがシステムに格納される発生源から正すか、データを分析・活用する前の段階でバッチ的にデータを再編成し、必要十分な状態に品質向上させるか、のいずれかである。
前者は、データの「重複」や「欠落」「意味不明」が発生しないように、データの入力を専門的に行う集約部門を設置し、入力やチェックルールを統一してメンテナンスを一元化するというデータガバナンス(統制)の選択肢である。現行業務への影響は大きいが、抜本的な解決策といえる。
後者は、ユーザ部門の業務負荷や業務変更インパクト等を加味して、従来通りデータは発生源入力する。その後で、データを常に最適化させるためのデータクレンジングを、対象データの分析・活用前に実施する方式である。
この企業では、お客様都合で案件の発生から発注・納品までのリードタイムが極めて短い業務特性が強かったことから、集約部門での入力が困難な状況にあった。また、商品数が多岐にわたり、購買管理システムに入力するデータをあらかじめ選択式にして、データ発生源での自由記述による入力を防ぐ方法も現実的ではなかった。とりわけ、IT業界などでは新しいハードウェア製品が次々に登場し、そこに搭載されるソフトやディスクやメモリー、ネットワーク機器等の組み合わせも限りなくある。あるタイミングで一度登録パターンを決めたとしても、陳腐化のスピードがあまりに速いため、データ発生源での規制には限界があると合理的な判断を下した。
そこで、入力されたデータの原本となった紙の見積書を現場から収集し、「**機器一式」と入力されているデータを、明細に基づいて個別の製品名称にブレークダウンして入力し直す「データ再生組織」を立ち上げることとした。
この結果、リアルタイムとはいかないが、一定のデータ鮮度を保ちつつ購入物品の単価比較やメーカー・ジャンルごとの購買傾向をみて、取引先への価格改定要求や最安値サプライヤーの絞込み、ボリュームディスカウント交渉等を定量的根拠データに基づいて実施することが可能になった。この企業では結果的に、自社データの資産価値を高めるための組織的・継続的な取り組みにより、年間数億円~数十億円のコスト削減を果たした。
このプロジェクトでは、「紙の見積書を逐次集めデータを再構成する」という地道な運用を、都度ルールや手法の改善を施しながら数年間にわたって実践・定着化させた。読者の皆さんは、ここまでの話を聞いて、「えっ!何てローテクなことをやっているの?」と驚かれるかもしれない。しかし、「システムだけでは解決されないデータの問題」に対してデータ再生組織をつくって愚直に取り組んだ同社は、確実に投じたコストよりずっと大きな成果を手に入れたのである。この事実を直視しなければならない。
(次ページでは、 日本ではなぜシステムがビジネスに大いに生かせたと実感しにくいのか、その理由について解説!)
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- 突然の事業環境変化にデータマネジメントを対応させる:第4回(2011/01/21)
- データマネジメントの全体最適化は、組織間でのデータ連携から:第3回(2010/09/21)
- 経営を左右するデータマネジメント:第1回(2010/05/26)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
