[ユーザー事例]
30年間歯周病に立ち向かうサンスター、次の一手はAIによる「ユーザー1人ひとりのオーラルケア支援」
2019年10月21日(月)五味 明子(ITジャーナリスト/IT Leaders編集委員)
歯ブラシ・歯ミガキなどのオーラルケアやヘルスケア製品のグローバル大手メーカーであるサンスターグループ。同社は2019年10月18日、歯ブラシ推奨Webサービス「ガム オーラルケア スマートコンシェルジュ」を同年11月8日より開始することを発表した。GoogleのAI技術を活用した新サービスで、消費者が手持ちのスマートフォンで自分の口腔内を撮影し、簡単な質問に答えると、AIが撮影画像をもとに歯と歯茎の状態を解析、ユーザー1人ひとりに適した歯ブラシをレコメンドする仕組みとなっている。
 写真1:サンスターグループ オーラルケアマーケティング部長 兼 GUMブランドマネジャーの仮屋光広氏
写真1:サンスターグループ オーラルケアマーケティング部長 兼 GUMブランドマネジャーの仮屋光広氏生活に密着した製品を提供するサンスターが、AIを活用したユニークなサービス「ガム オーラルケア スマートコンシェルジュ」を立ち上げた。サンスターグループ オーラルケアマーケティング部長 兼 GUMブランドマネジャーの仮屋光広氏(写真1)によると、同社のデンタルケア製品ブランド「GUM」は今年で30周年を迎え、約300億円規模の事業に成長しているという。
「これまでの蓄積を基に、次の30年は歯周病予防から"Mouth & Body"、口腔から全身の健康を考え、サポートするステージへと進化させていく。今回の新サービスはそうした次世代への取り組みの一環である」と仮屋氏は説明(図1)。AIの導入をきっかけにオーラルケアのインサイト向上を図っていくというサービスプロジェクトになっている。
 図1:30年にわたり原因療法にフォーカスし歯周病と戦ってきたGUMブランドが次に目指すのは、オーラルケアからの全身健康のサポート。AIによる歯ブラシ選びのサポートは最初の取り組みとなる(出典:サンスターグループ)
図1:30年にわたり原因療法にフォーカスし歯周病と戦ってきたGUMブランドが次に目指すのは、オーラルケアからの全身健康のサポート。AIによる歯ブラシ選びのサポートは最初の取り組みとなる(出典:サンスターグループ)拡大画像表示
スマートコンシュルジュサービスの仕組み
ガム オーラルケア スマートコンシュルジュはどんなサービスなのか。以下は、サンスターが説明した利用の流れである(図2)。
(1)ユーザーがスマートフォンから、コンシュルジュサービスのWebサイト、画面1)にアクセス
(2)同サイトのフォームで年齢、性別などの質問に回答
(3)自身の口腔の写真をスマホのカメラで撮影
(4)みがき残しをしやすい箇所やブラッシングのしかたの注意などを画面で表示
(5)AIによる画像解析を基に、ユーザーそれぞれの口腔状態に適した歯ブラシや歯間ブラシなどを提案
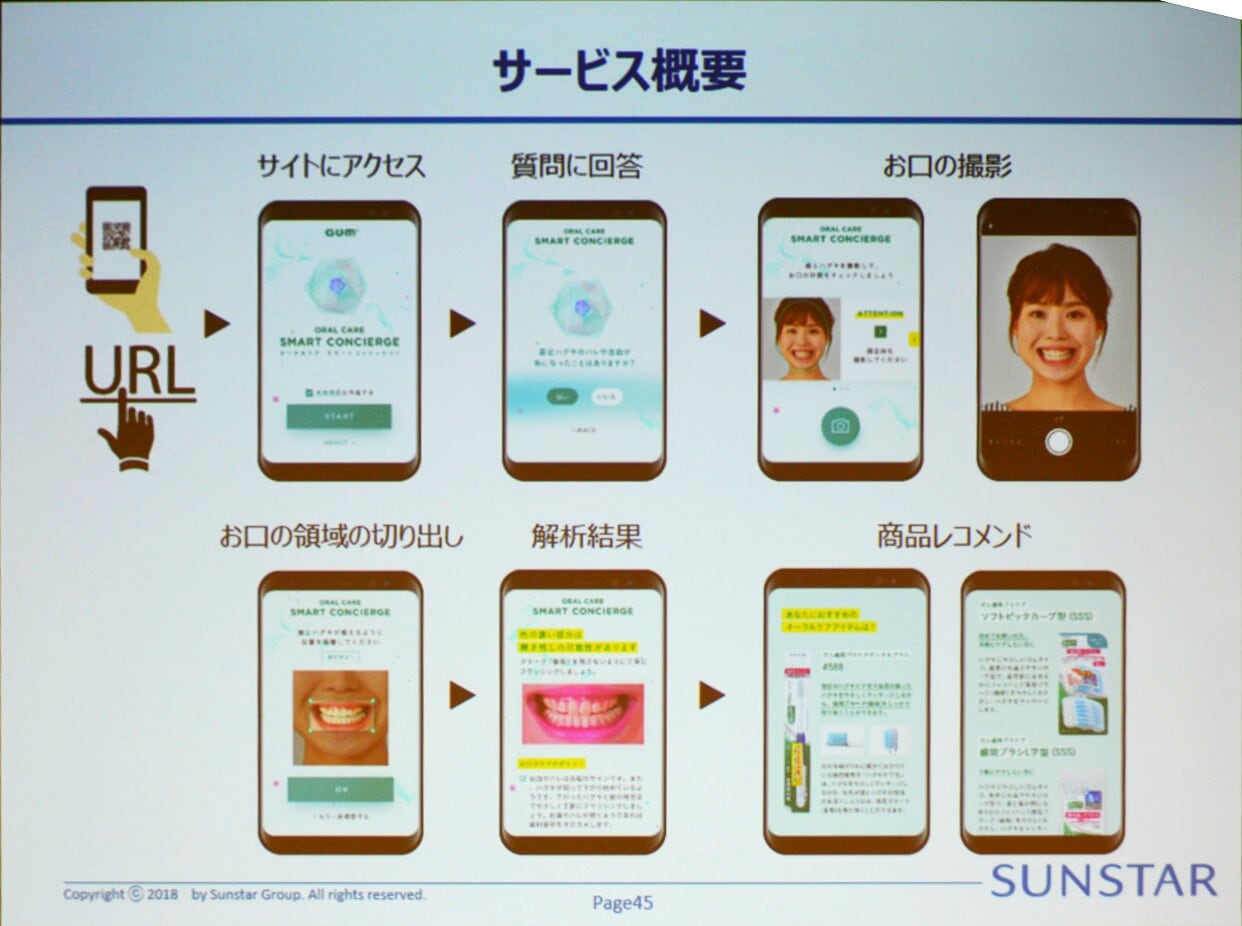 図2:ガム オーラルケア スマートコンシュルジュのサービス利用の流れ。手持ちのスマホを使って質問に回答後、自分で口腔内の写真を撮影。それをAIが画像解析した結果から個々にマッチした歯ブラシが提案される(出典:サンスターグループ)
図2:ガム オーラルケア スマートコンシュルジュのサービス利用の流れ。手持ちのスマホを使って質問に回答後、自分で口腔内の写真を撮影。それをAIが画像解析した結果から個々にマッチした歯ブラシが提案される(出典:サンスターグループ)拡大画像表示
 画面1:ガム オーラルケア スマートコンシュルジュのWebサイト。サービス開始は11月8日以降で、推奨環境はiOS 12以降またはAndroid 6以降のスマートフォン(出典:サンスターグループ)
画面1:ガム オーラルケア スマートコンシュルジュのWebサイト。サービス開始は11月8日以降で、推奨環境はiOS 12以降またはAndroid 6以降のスマートフォン(出典:サンスターグループ)拡大画像表示
同サービスの技術上の肝となる口腔写真解析AIは、検討期間も含め、サンスターが約1年をかけて構築した教師あり学習(Supervised Learning)モデルがコアとなっている。サンスターは、精度の高いモデルを構築するにあたり、最も重要となるプロセスを教師ラベル付けにしている(図3)。
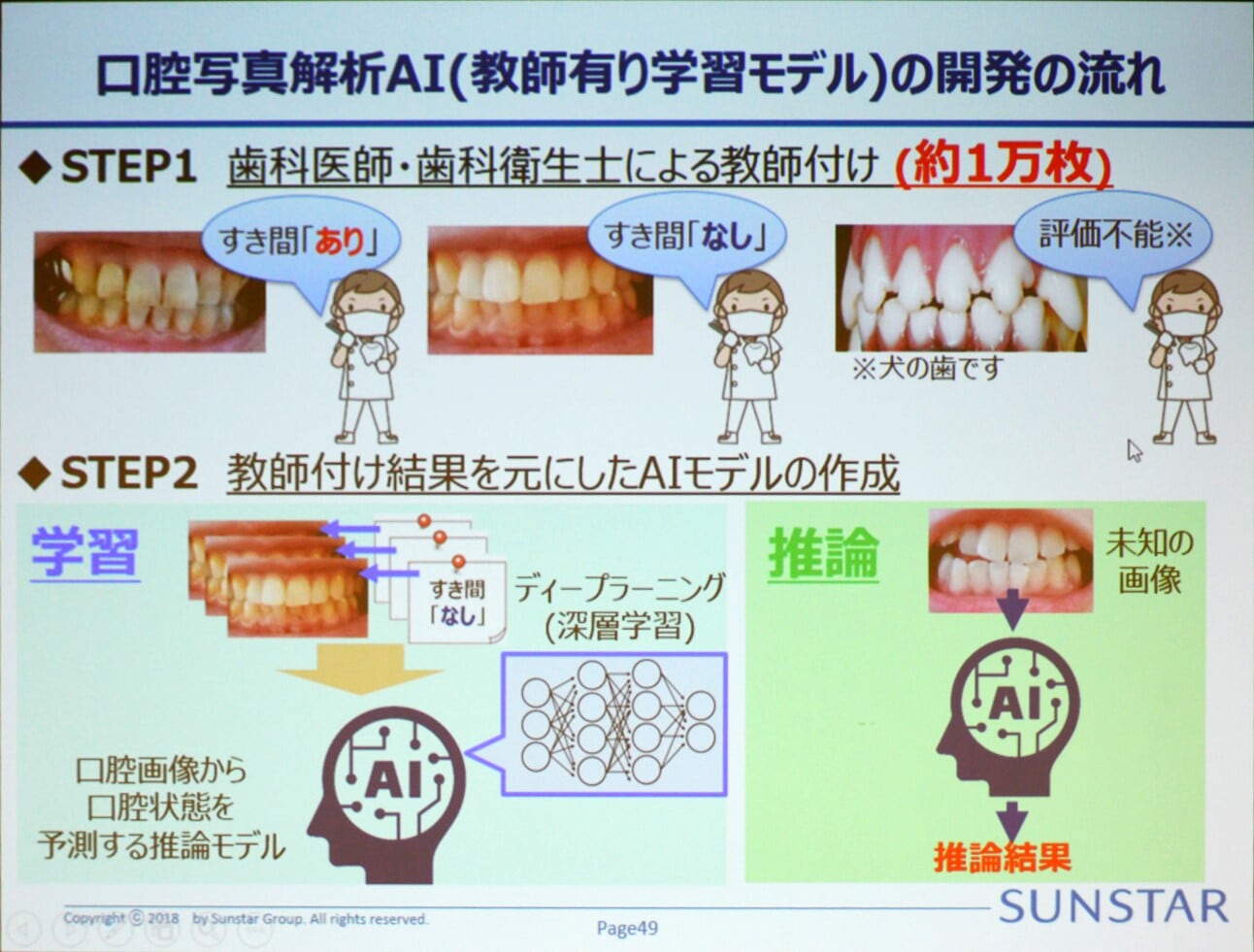 図3:口腔写真解析AIの仕組み。学習と推論にCloud AutoMLやCloud Vision APIを、ディープラーニングの基盤にTensorFlowを採用(出典:サンスターグループ)
図3:口腔写真解析AIの仕組み。学習と推論にCloud AutoMLやCloud Vision APIを、ディープラーニングの基盤にTensorFlowを採用(出典:サンスターグループ)拡大画像表示
その作業は膨大だった。年間で約3万人が訪れるというサンスター歯科診療所で集めた約1万枚の口腔写真データに対し、同診療所で働く第一線の歯科医師および歯科衛生士によって、約2万8000回の教師ラベル付けを実施している。1枚の写真に対し、複数の評価項目(すきまのあり/なし、すきまの程度、歯茎下がりのあり/なし、歯並びの状態など)が設定されることから、作業効率を図るため独自のラベリングを定義した教師ラベル付けツールも開発したという。
この作業結果を基に、100~1000層から構成されるニューラルネットワークによるディープラーニング(深層学習)を繰り返し、口腔画像から口腔状態を予測する推論モデルを構築した。このモデルに基づき、ユーザーの歯の隙間や歯茎の下がり具合といった項目をチェックして口腔状態を把握し、適切な歯ブラシを推奨する(図4)。サンスターグループ 新規事業研究開発部 研究員の太田安里氏(写真2)によれば、奥歯など写真からは見えない部分があっても「前面の歯茎の状態から、口腔内全体を推測することが可能」(同氏)だという。
 図4:AIを用いた口腔写真解析による商品のレコメンド(出典:サンスターグループ)
図4:AIを用いた口腔写真解析による商品のレコメンド(出典:サンスターグループ)拡大画像表示
 写真2:サンスターグループ 新規事業研究開発部 研究員の太田安里氏
写真2:サンスターグループ 新規事業研究開発部 研究員の太田安里氏AI技術として、サンスターは、複数のGoogleサービスを採用した。例えば、顔画像からの口腔領域抽出には、独自に定義したラベルに従って学習可能な「Cloud AutoML Vision」と膨大な事前定義済みのラベルを用いて画像を高速に分類。オブジェクトの高精度な自動検出を得意とする「Cloud Vision API」を活用している。また、口腔画像からの口腔状態解析には、Googleがオープンソースで公開しているディープラーニングフレームワーク「TensorFlow」を活用している。
Cloud AutoML VisionやCloud Vision APIは現時点ではまだベータ版だが、採用に迷いはなかったのか。この点について太田氏は、「他社製品も検討はしたが、物体、特に口腔という顔のパーツを検出し、その画像を基に学習モデルを構築するというプロセスにおいては、Googleのサービス群が最も扱いやすかった。また、TensorFlowはディープラーニング基盤として圧倒的なシェアがあり、既存のさまざまな情報が参照しやすかった点も大きい」と説明する。
ベータ版とはいえ、Cloud Vision APIは、膨大なコンテンツを管理する現場で支持されており、米ニューヨークタイムズ(The New York Times)のような大手メディア企業での採用も多い。教師付けされた約1万枚の画像データを基に推論モデルを構築するという今回のようなケースには最適だったと言える。太田氏は、自社の取り組みを次のように評価して抱負を語る。
「約1万枚というデータ量は決して多いとは言えないかもしれない。だが、一メーカーが収集した量としては十分評価できると考えており、さらに教師付けというプロセスを丁寧に行ってきた。今回のサービスは我々にとっても新しいチャレンジではあるが、消費者に対し、一定レベル以上の精度で提供できるという確信を得ている。今後は市場の声を聞きながらサービスの改善を続け、場合によっては新しいデータを使った再学習プロセスなども検討していきたい」(太田氏)
●Next:消費財分野でのDXアプローチを生んだ背景
会員登録(無料)が必要です


- 1
- 2
- 次へ >



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
