[市場動向]
NTT、LLMの推論能力を用いた視覚読解技術を開発、教師あり学習に匹敵
2024年4月12日(金)日川 佳三(IT Leaders編集部)
NTTは2024年4月12日、大規模言語モデル(LLM)の推論能力を活用して、文書をグラフ画像などの視覚情報も含めて理解する視覚読解技術の研究成果を発表した。テキスト情報だけでなく、折れ線/棒グラフなどの画像化した資料を読み取って全体の内容を理解して回答するといった利用が可能になる。検証では教師あり学習モデルに匹敵する性能が得られたという。研究成果はすでに、LLM「tsuzumi」における文書画像をLLMの表現に変換するアダプタとして実装している。
NTTは、文書をグラフ画像などの視覚情報も含めて理解する視覚読解技術を実現し、その研究成果を発表した。大規模言語モデル(LLM)の推論能力を活用することで、テキスト情報だけでなく、折れ線/棒グラフなどの画像化した資料を読み取って全体の内容を理解して回答するといった利用が可能になる。
検証では教師あり学習モデルに匹敵する性能が得られたという。研究成果はすでに、LLM「tsuzumi」における文書画像をLLMの表現に変換するアダプタとして実装している。
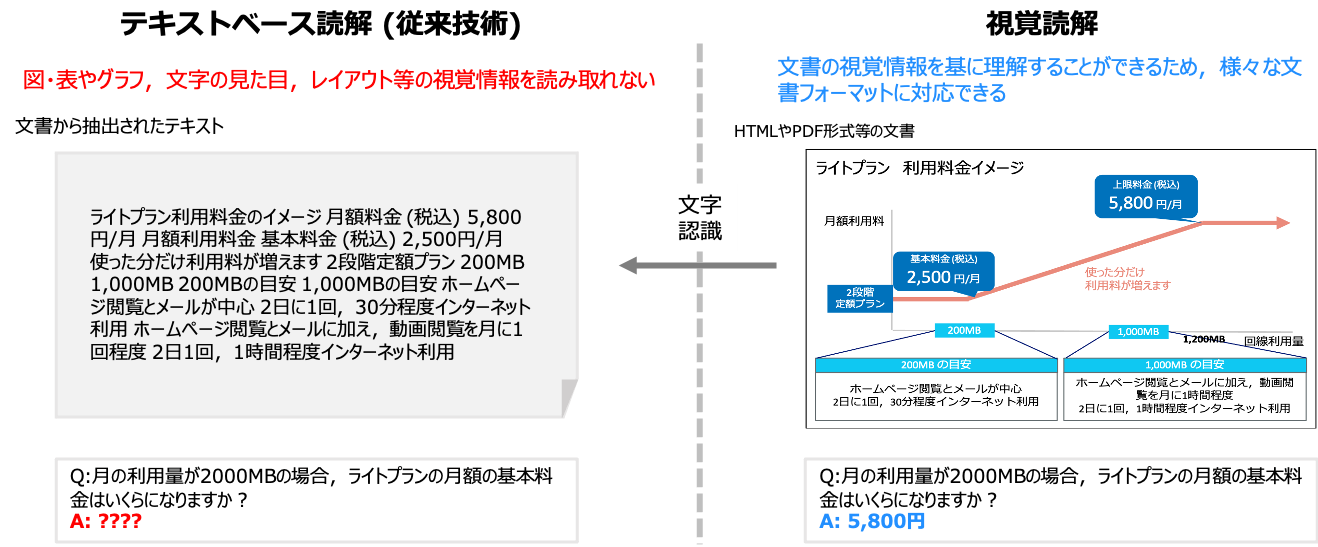 図1:抽出したテキストを読解する従来方法と、文書の視覚情報を読解する方法の比較(出典:NTT)
図1:抽出したテキストを読解する従来方法と、文書の視覚情報を読解する方法の比較(出典:NTT)拡大画像表示
「業務などで扱う文書は、テキストや視覚要素(アイコンや図表など)を含んでおり、多様な形式が存在する。こうした文書を読解し理解する技術の実現は、AI分野における重要課題の1つであるが、LLMには、文書中のテキスト情報しか理解できない限界があった」(NTT)
この問題に対してNTTは、人間の情報理解と同様に、文書を視覚情報から理解する視覚読解技術を提唱し、研究開発を進めてきた(図1)。だが、同社によると、これまでの視覚読解技術は、請求書から情報を抽出するといった任意のタスクに対して対応できなかった。目的のタスクごとに一定数のサンプルを用意して学習させない限り、所望のタスクで高い性能を出すことは難しかったという。
今回の研究では、汎用的な言語理解・生成能力を持つLLMをベースに、任意のタスク用の学習を行わなくても応答できる、高い指示遂行能力を視覚読解モデルで実現することを目指した。具体的には、テキスト情報しか理解できないLLMに対して、どのように文書画像に含まれる図表などの視覚情報をテキストと融合させてLLMに理解させるかの課題解決に取り組んでいる。
●Next:LLMの推論能力を用いた視覚読解技術の仕組み
会員登録(無料)が必要です





- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
