大量のデータを扱うWebサービス事業者たちが生み出した「分散キー・バリューストア」。オープンソースとして公開されているものだけでも、その数は優に数十を超える。最近では、RDBを補完する手段として、企業向け製品を投入するベンダーも増えてきた。
数十テラバイトを超えるデータを格納したい、あるいは、1日あたり数億件単位で押し寄せるデータアクセスを高速に捌きたい。そうしたニーズに直面したWebサービス事業者が選んだのは、性能やコストなど、自社の要件に合う新しいデータベースを開発するという道だった。Googleの「Bigtable」や、Amazonの「Dynamo(ダイナモ)」などを筆頭に、Facebookの「Cassandra(カサンドラ)」や、楽天の「ROMA(ローマ)」など、さまざまな企業が後に続いた。RDBと異なるアーキテクチャを持つことから、「NoSQL(Not Only SQLの略)」と呼ばれ、多くがオープンソースとして公開されている。中でも最もソフトの数が多いのが、「分散キー・バリューストア(分散KVS)」である。
RDBよりも安価に大量のデータを保管できる。こうした特性は、一般の企業が抱える問題の解決にも役立つはずだ。例えば、コストの都合で破棄していたPOSデータやWebログを保管する。あるいは、法制度対応などの理由で保持するデータの保管コストを下げるといった使い方が考えられる。
一般企業でのニーズが増えることを見込んだ大手ベンダーが、自社のポートフォリオに分散KVSを組み込む動きも出てきている。例えば、日立製作所は2012年2月、インメモリー型の分散KVSとも言うべき「uCosminexus Elastic Application Data store(EADs)」をリリースした。同社が想定する用途の1つがM2Mである。「センサーデータのように、大量、かつ高頻度で発生するデータはRDBが苦手な分野。一旦、EADsがデータを引き受けて、バックエンドでRDBに書き出す」(日立製作所の梅田多一主任技師)。今回は、分散KVSの仕組みをおさらいしよう。
単純なデータモデル
シンプルな機能
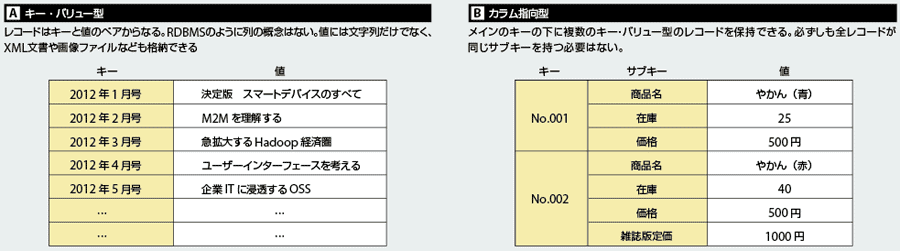
分散KVSの最大の特徴は、シンプルなデータモデルだ。値(データ)と、それを識別するためのキーのペアからなる。値を取り出したり、変更したりする際はキーを指定する。値には、文字列だけでなく、XML文書や画像どのバイナリデータも格納できる。RDBのように、複数の列を持つテーブルは基本的に定義できないが、一部のソフトでは、1つのキーに対して、キーと値のペアのリストを紐づけられる。例えば、製品名というキーの下に、製品名や製品コード、価格など、複数のサブキーを保持できる。一般的な分散KVSと区別して、「カラム指向型データベース」などの呼称で分類される場合もある。
レコードの参照や変更には、独自のライブラリを用いる場合が多い。例えば、アマゾンウェブサービスの「Amazon Dynamo DB」は、Javaや.NET、PHP、Python、Ruby向けのクライアントライブラリを用意。プログラムから関数を呼び出して、データの登録・更新、削除、値の検索などを行う。ただし、RDBのように複雑な分析クエリを使うことはできない。詳細な分析をする場合は、DWHなどに取り込んだり、並列分散フレームワーク「MapReduce」を使ったりする必要がある。また、トランザクション機能を備えるものは少ない。
マスター・スレーブ型とP2P型の2タイプが存在
分散KVSは、複数のサーバーを使って、単一のサーバーで対応できない大量のデータを格納、処理する。それを可能にするのが、サーバーを束ねて、1つのクラスターとして扱う仕組みだ。データの所在を把握したり、サーバーの死活状況を監視したりする。製品によって細かい実装は異なるが、大きく「マスター・スレーブ型」と「P2P型」の2タイプに分類できる(図2)。
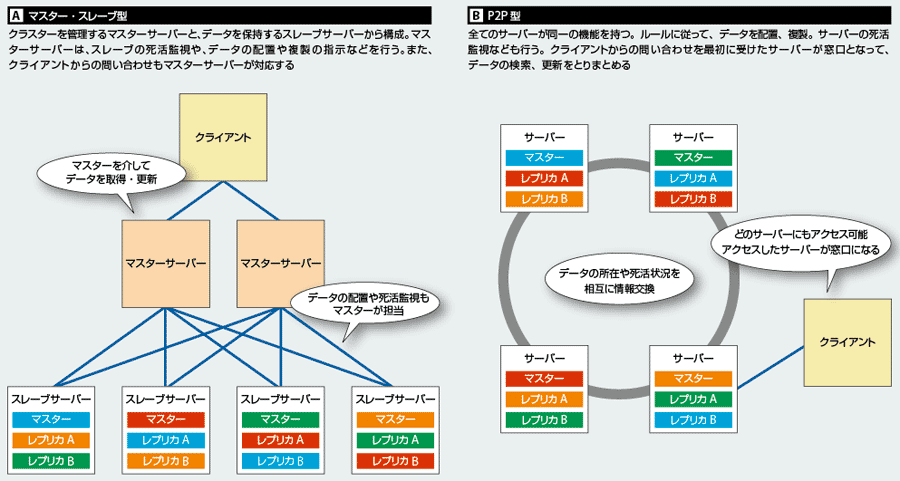
マスター・スレーブ型は、クラスターを管理するマスターサーバーと、データを保管するスレーブサーバーからなる。マスターはクライアントから要求に応じて、スレーブにデータの検索や更新を指示する。また、各スレーブの稼働状況や負荷などを監視し、データの配置を調整したり、複製を命じたりする。マスターが単一障害点になるため、冗長化する場合が多い。
一方、P2P型は、マスターサーバーを持たず、すべてのサーバーが同じ機能を持つ。各サーバーが相互に通信してデータの所在を把握。クライアントからのリクエストに応じて、自分自身や他のサーバーからデータを取り出したり、配置ルールに従ってデータを書き込んだりする。また、各サーバーが相互に稼働状況を監視する。単一障害点を持たないのが特徴だ。
クラスター内のサーバーにデータをバランスよく配置
分散構成ならではの課題に対処する機能を備えているのも分散KVSの特徴だ。例えば、データの分散配置。クラスター全体のスループットを高めるには、特定のサーバーに負荷が集中しないよう、バランスよくデータを配置する必要がある。しかも、データ量やサーバー数は運用の過程で変化するため、常に見直さなければならない。多くの分散KVSは、「コンシステントハッシング」や「シャーディング」などと呼ばれる手法を使って、データを分散させている(図3)。
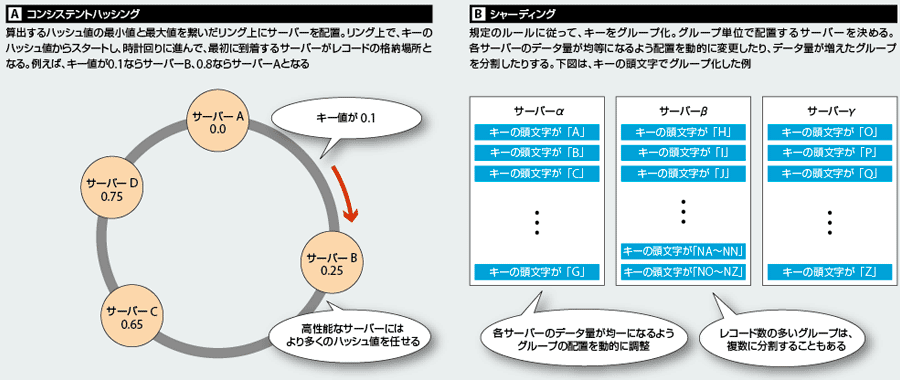
また、安価なサーバーを大量に並べる分散KVSでは、ハードウェア障害が生じる可能性も高い。サーバーの不具合でデータが消失してしまったときに備えて、複数の物理サーバーにデータの複製を保持するものが多い。
ネットワーク障害によってクラスターが複数に分裂する。これも分散構成ならではの課題だ。データの整合性を優先して、クライアントからのアクセスに対応するグループを限定する、あるいは、データの整合性が崩れることを容認して、各グループでのデータの閲覧や更新を許可するといった具合に、ソフトごとに障害対応の仕組みを備えている。以下、特徴的な製品をいくつか紹介しよう。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- 注目のメガネ型ウェアラブルデバイス[製品編](2015/04/27)
- メインフレーム最新事情[国産編]NEC、日立、富士通は外部連携や災害対策を強化(2013/09/17)
- メインフレーム最新事情[海外編]IBM、ユニシスはクラウド対応やモバイル連携を加速(2013/09/17)
- データ分析をカジュアルにする低価格クラウドDWH(2013/08/02)
- 「高集積サーバー」製品サーベイ─極小サーバーをぎっしり詰め込み、用途特化で“非仮想化”の強みを訴求(2013/07/23)



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
