これまで全社的なデータ活用基盤の構築は、データウェアハウスやデータレイクにあらゆるシステムからデータを集めることを前提としてきた。ところがSAPは、「もうデータを1カ所に集める必要はない」とこの“常識”を覆そうとしている。SAP HANAのクラウドサービスを活用し、データアクセスの“速さ”とデータ提供の“早さ”を実現する次世代データ活用基盤のあり方についてキーパーソンが語った。
データを集めることにコストを掛けるのは本末転倒
多くの企業が競争力の強化を目指し、KPIの見える化や業務標準化に取り組んでいる。しかし、その足元を眺めてみると業務や部門ごとにシステムがサイロ化し、横の連携はほとんどできていないのが実情だ。
全社的にERPを導入してBPR(ビジネスプロセスリエンジニアリング)を実現できればよいのだが、一足飛びにそこにたどり着くのもなかなか難しい。そこで一般的に採られるのが、データレイクやデータウェアハウスにさまざまなシステムからデータを収集・蓄積し、さらにそこから目的別のデータマート(集計済みのテーブル群)を作ってデータ活用を行うというアプローチである。
 SAPジャパン株式会社 プラットフォーム & テクノロジー事業部 SAP HANA CoE シニアディレクター 椛田 后一 氏
SAPジャパン株式会社 プラットフォーム & テクノロジー事業部 SAP HANA CoE シニアディレクター 椛田 后一 氏これに対して、「データを1カ所に集めることに躍起になるのはもうやめにしませんか」と独自の考え方を示すのは、SAPジャパンの椛田后一氏(プラットフォーム&テクノロジー事業部 SAP HANA CoE シニアディレクター)だ。「ビジネス現場の全員参加型のデータ活用を考えた時に最も重要なのは、データアクセスの“速さ”と、欲しいデータが見られるまでの“早さ”なのです」と椛田氏は語る。
実際、データレイクやデータウェアハウスに明細レベルのデータを集めることには多大なコストと時間がかかる。さらにそこから夜間バッチなどで集計・加工処理を行い、目的に応じたデータマートを作るとなれば思った以上のタイムラグが生じてしまう。リアルタイムのデータ活用には程遠く、データを集めることに多大な労力とコストを掛けるのは本末転倒と言わざるを得ない。
AI活用についても同じことが言える。「多くの企業がAIに特化した開発・運用環境を構築しようとしていますが、そもそも学習に利用するデータがデータベース内に集まっているならば、その基盤上でAIの開発・運用まで行った方がスピーディに対応できるはずです」と椛田氏は強調する。
「クラウド活用」と「データマートレス」で課題解決
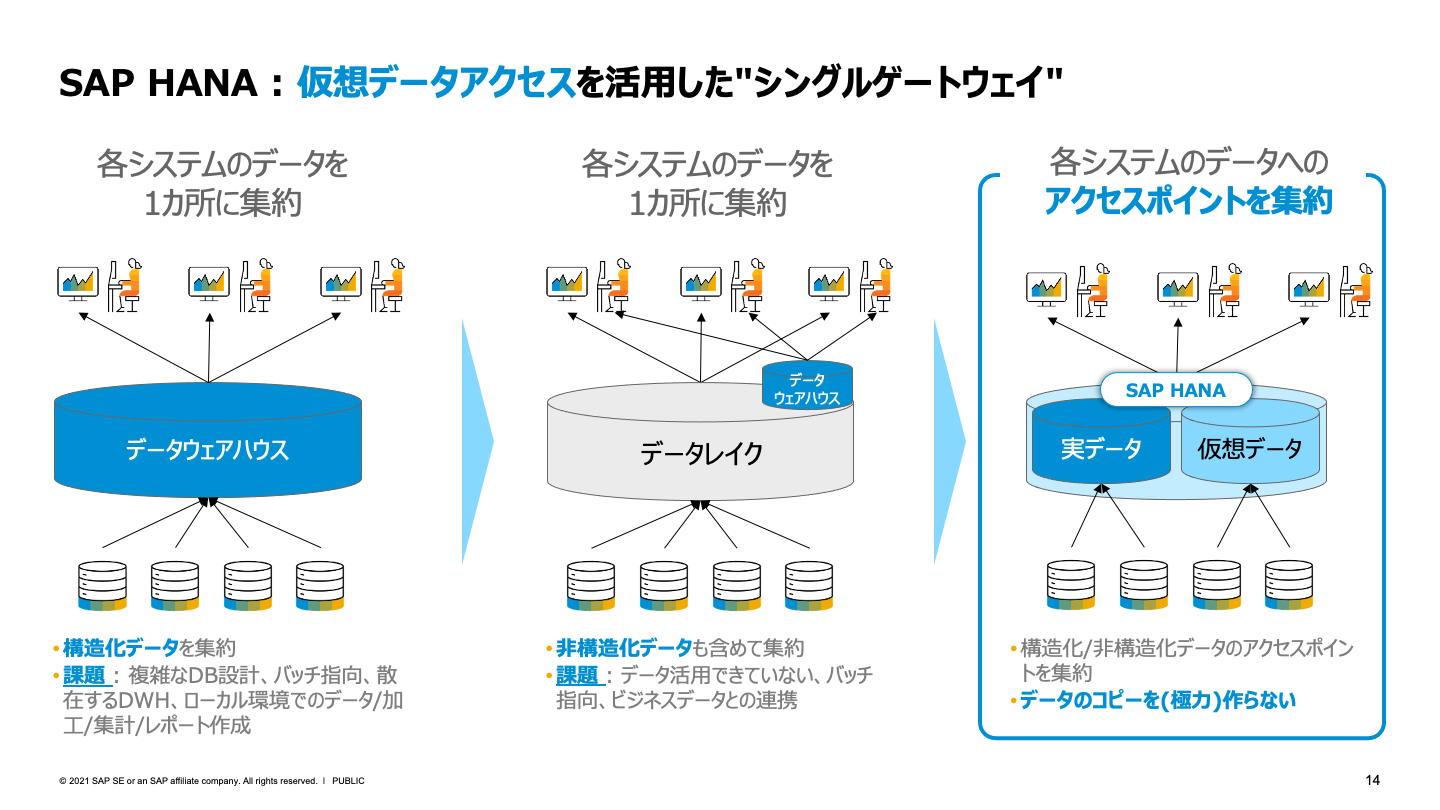
データアクセスの“速さ”と、欲しいデータが見られるまでの“早さ”を兼ね備えた全員参加型のデータ活用基盤は、どうすれば実現できるのだろうか。椛田氏が示すのは「クラウド活用」と「データマートレス」というキーワードである。「明細データを瞬時に集計するSAP HANAがクラウドサービスとして提供している仮想データアクセスを利用すれば、物理的なデータマートを作る必要はありません。外部のデータソースをリアルタイムに連携し、経営層も業務現場も1ファクトでなおかつリアルタイムのデータに基づいて意思決定を行ったり、分析したりできます」と椛田氏は語る。
 仮想データアクセスの概要
仮想データアクセスの概要拡大画像表示
データソースが複数ベンダーのシステムに分散していても問題はない。SAP HANAには異なるシステムに散在しているデータを仮想テーブルとして統合する機能があり、あたかも実際のテーブルがあるかのような感覚でアクセスできるのだ。たとえばOracle DatabaseやMicrosoft SQL Serverなどにも簡単にアクセスできる。従来のようにETL(抽出/変換/登録)ツールを使ってデータを集約するといった手間は不要となる。
ただ、それらのデータソースの中には基幹系をはじめミッションクリティカルなシステムもあり、毎回リモートアクセスするとなればオーバーヘッドがかかり、パフォーマンスに影響を及ぼすことを懸念するかもしれない。そのような場合は「管理画面からスイッチ1つでレプリケーションを行うことが可能です」と椛田氏は語る。以降はこのレプリケーションされたデータに対して自動的にアクセスが行われるため、データソースに影響を及ぼすことなく、SAP HANA側でも“速い”データ活用を実現できる。
特別な設計や構築を行うことなく、しかもクラウド上にこうした柔軟なデータ活用基盤を実現できるのは、SAP HANAならではのメリットだ。これまでデータマートの開発・運用に費やしてきた工数を大幅に削減し、IT部門の業務負荷を軽減することが期待できる。また、業務部門の要望に迅速に応えることが可能となり、結果として全社での情報活用レベルを向上させることができる。
誰でもAIの予測モデル作成が可能に
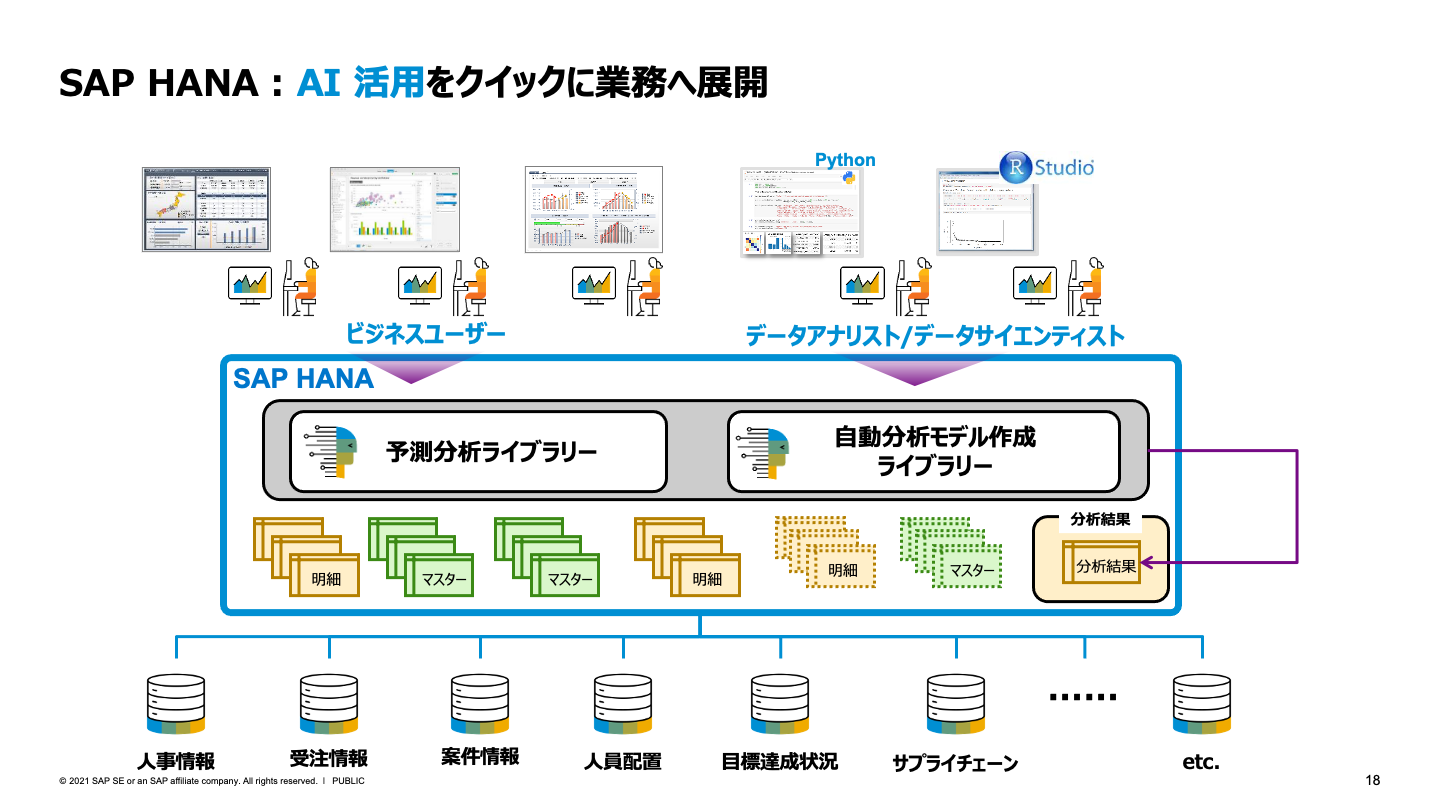
もう1つのポイントとして、SAP HANAが提供するクラウドネイティブなインメモリーデータベースサービスはAI活用も容易にする。SAP HANA上に実装された、予測分析や自動分析モデル作成のための豊富なライブラリを活用できるのだ。「履歴データや実績データを学習させて予測モデルを作成できるのは言うまでもなく、新たなデータをどんどん取り込んで再学習や強化学習を行うといったAIのライフサイクル全般をSAP HANA上で実行することができます」(椛田氏)。
 進化著しいAIテクノロジーを業務に展開
進化著しいAIテクノロジーを業務に展開拡大画像表示
しかもPythonなどの言語のスキルを必須としない。「Oracle DatabaseやSQL Serverなどの知識をもったデータベースエンジニアであれば、SQLのプロシージャレベルで予測モデルを定義したり、差分情報を投入して再学習させたりすることも可能です」と椛田氏は強調する。データサイエンティストに頼らなくても、はるかに層の厚いデータベースエンジニアが自らAIのライフサイクルを回せるようになるわけだ。
例えば、誰が購入してくれそうか、退職しそうか、どの機器が壊れそうかを予測する「分類分析」、さまざまな要因から売上がいくらになりそうかを予測する「回帰分析」、顧客がどのようなグループに分かれるかを分析する「セグメンテーション/クラスタリング」、顧客が誰と頻繁に連絡を取り合っているかを可視化する「ソーシャルネットワーク分析」、顧客に対してどの商品を勧めるべきかを決定する「リコメンデーション」、今までの傾向から売上はいくらになりそうかを分析する「時系列予測」など、すべてSAP HANAで対応できる。
また、SAP HANAからSQL文を自動生成し、推論結果をわざわざ別のテーブルに出力することなく、リアルタイムに予測値を得るといった高度なAI活用も可能だ。こうしたことが可能なのは、あらゆるデータへのアクセスポイントを1つに集約する「シングルゲートウェイ」をSAP HANAが体現しているからにほかならない。
 データを1カ所に集めないという新機軸を打ち出す
データを1カ所に集めないという新機軸を打ち出す拡大画像表示
繰り返すが各システムのデータをデータウェアハウスやデータレイクに集めようとすると、そのことだけに全精力をつぎ込むことになりかねず、肝心の活用やパフォーマンス、運用まで手が回らず、一部のユーザーにしか使われないものになってしまう。これに対してSAP HANAは「まず活用ありき」の考え方を徹底することで、誰もが恩恵を受けられる次世代のデータ活用基盤を実現するのである。

●お問い合わせ先
SAPジャパン株式会社
フリーダイヤル 0120-786-727
Web https://www.sap.com/japan/registration/contact.html
製品URL https://www.sap.com/japan/products/hana/cloud.html
- 経営革新の核となるデータ活用の考え方~経営・顧客・設計・製造が連動したDX基盤のグランドデザインを描く(2021/05/06)
- MDMの効果を経営層に納得させるために―ROI可視化に効く3つの観点とは?(2021/04/26)
- データマネジメントで見過ごしがちな重要ポイント! 今こそ“ストレージ”を再考すべき時期(2021/04/21)
- データ駆動経営を実現する組織の在り方とは? 事例で学ぶデータアーキテクトのミッション(2021/04/20)
- 点在するデータリソースをワンストップで利用できる「データ仮想化プラットフォーム」の実力(2021/04/16)




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
