データの重複個所を検出して排除する「重複排除」技術に注目が集まる。バックアップのみならず本番環境でもデータが爆発的に増えているからだ。専用ソフトウェアやアプライアンスなど、重複排除機能を実装する製品の最新動向を追った。
「転ばぬ先の杖」。企業システムにおけるデータのバックアップは、こう表現される。ただし、情報爆発の言葉通りに企業が扱うデータの量は増加の一途をたどっている。重い体を支えるには「杖」にも工夫が欠かせない。
膨大なデータを効率的にバックアップする手法として脚光を浴びている技術が「重複排除」である。詳しくは後述するが、データを数KB単位に細分化し、同じものを抽出して徹底的に取り除くのが基本的な仕組みだ。限られたディスク(あるいはテープライブラリ)の容量を有効活用する上で、要注目の技術だ。
ファイル単位の限界を超える
重複排除の仕組みを解説する前に、これまで一般的だったバックアップの方法を整理しておこう。
膨大なデータを毎日フルバックアップするのは、それに要する時間やハード資産の兼ね合いから非現実的だ。実際には、休業日の日曜日にフルバックアップを実行。それを起点として平日は、日々増えた(変更のあった)分のデータだけを新規にバックアップするという週次サイクルを回す企業が多い。ここには「差分バックアップ」と「増分バックアップ」がある。
差分方式は、起点とするデータからの変化を日々バックアップする。これに対し、増分方式は、前日からの変化をバックアップ対象とする。後者の方が毎日のバックアップ量が小さくて済むが、リストアが必要となった時の作業手順が複雑になる(図1)。
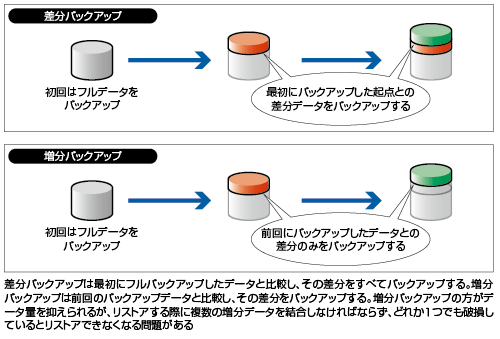
差分、増分のいずれにしても、「変化」はファイル単位でとらえるのが一般的だ。しかも同じファイルを異なるフォルダに複数保存する場合、それらすべてがバックアップ対象となる。Aというファイルを添付したメールを10人に同報すると、この日のメールサーバーの差分/増分バックアップでは、Aは10個も重複して保存される。
こうした無駄に切り込むのが重複排除の技術である。ファイル単位でバックアップ対象を見極めるのではなく、さらに細かなセグメントに分割して内容を比較。ここで同じセグメントは1つしかバックアップしない仕組みを徹底し、対象データを大幅に削減する(図2)。大元のファイルが、どのセグメント群で構成されていたかという「紐づけ」情報は別途管理している。
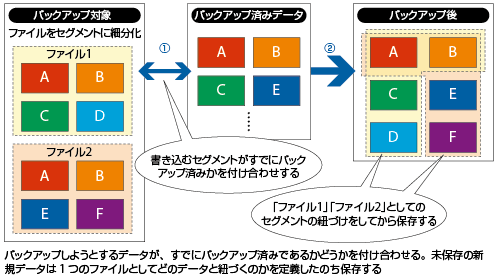
眼前に玩具のブロックを思い浮かべてほしい。赤、青、黄のブロック合計100個で城を組み立てたとする。これをファイルと見立てて重複排除を当てはめると、保存するのは色別のブロック3つのみ。別途、どこにどのブロックが使われていたかという情報があればよいという考え方だ。「保存先容量を重複排除で最大25分の1まで縮小できた実績がある」(日本IBM ソリューション担当部長 システムズ&テクノロジー・エバンジェリスト 佐野正和氏)。
重複排除機能を備える製品を次ページの表にまとめた。大きくはソフトウェア、バックアップ専用アプライアンス、ストレージに分かれる。それぞれ特徴や機能を概説しよう。
バックアップソフト
どこで重複排除するかに選択肢
バックアップソフトは、どの場所で重複排除を実施するかで大きく2つに分かれる。1つは、PCやファイルサーバーで実施するもの。バックアップ用ストレージにデータを転送する前に対象データを減らせるため、ネットワークへの負荷を軽減できる。もう1つは重複排除専用のサーバー/ストレージに導入するソフトだ。ネットワークにある程度の帯域を必要とするが、クライアントPCの負担はない。
これまでは、どちらか一方に機能を絞ったものが中心だったが、2009年末から今年にかけて、ユーザーが自由に設定できる製品が相次ぎ登場した。シマンテックが2010年2月に発表した「Net Backup 7」と「Backup Exec 2010」は、重複排除の実施をクライアントか専用サーバー/ストレージかを選べるほか、他の重複排除機能を備えるアプライアンスやストレージと連携して高速処理する機能も持たせた。2009年11月に発表したアクロニス・ジャパンの「Acronis Backup & Recovery 10」も同様に、重複排除の実施場所を選択できる。
ネットワークとクライアントへの負荷軽減という点において、IBMの「IBM Tivoli Storage Manager Fast Back V6.1」はユニークなアプローチで改善を図る。PCでファイルを更新すると、その瞬間に差分データをバックアップ用ストレージに転送。蓄積した差分データに対して重複排除を実施する。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- 注目のメガネ型ウェアラブルデバイス[製品編](2015/04/27)
- メインフレーム最新事情[国産編]NEC、日立、富士通は外部連携や災害対策を強化(2013/09/17)
- メインフレーム最新事情[海外編]IBM、ユニシスはクラウド対応やモバイル連携を加速(2013/09/17)
- データ分析をカジュアルにする低価格クラウドDWH(2013/08/02)
- 「高集積サーバー」製品サーベイ─極小サーバーをぎっしり詰め込み、用途特化で“非仮想化”の強みを訴求(2013/07/23)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
