大規模な構造化データと非構造化データを透過的に、同じような操作で分析可能にする--。日本テラデータは3月7日、こんなコンセプトの製品群を発表した。
「Teradata Unified Data Architecture(UDA)」と呼ぶデータアクセスや管理に関するアーキテクチャ、そのための一連のソフトウェア製品、そして米国で昨年10月に発表済みの「Teradata Aster Big Analytics Appliance」というアプライアンス製品である。それにしても構造化データと非構造化データを同じように分析できるというのは、いったいどんな仕組みなのか。類似製品がないこともあって分かりやすくないので、順に解説しよう。
まず、Teradata UDAから。同社は「大規模なデータを分析するには、構造化データはDWH、非構造化データはHadoopという具合に、データ管理や分析基盤を別々に構築し、個別に運用せざるを得ない。SQL言語でアクセスできるDWHに対し、HadoopではJavaを使う必要があるなど、求められるスキルも異なる。当然、それだけ多様な人材も必要になる。このような問題を解決するのがUDAだ」という。
ただしUDAはその名前から想起されるような、構造化データと非構造化データをUnified(統一)するためのアーキテクチャではない。それが可能なら分析基盤は1つで済むかも知れないが、そんなアーキテクチャはたぶん存在しない。そうではなく、データへのアクセス方法やデータ分析の基盤を統一するものである。
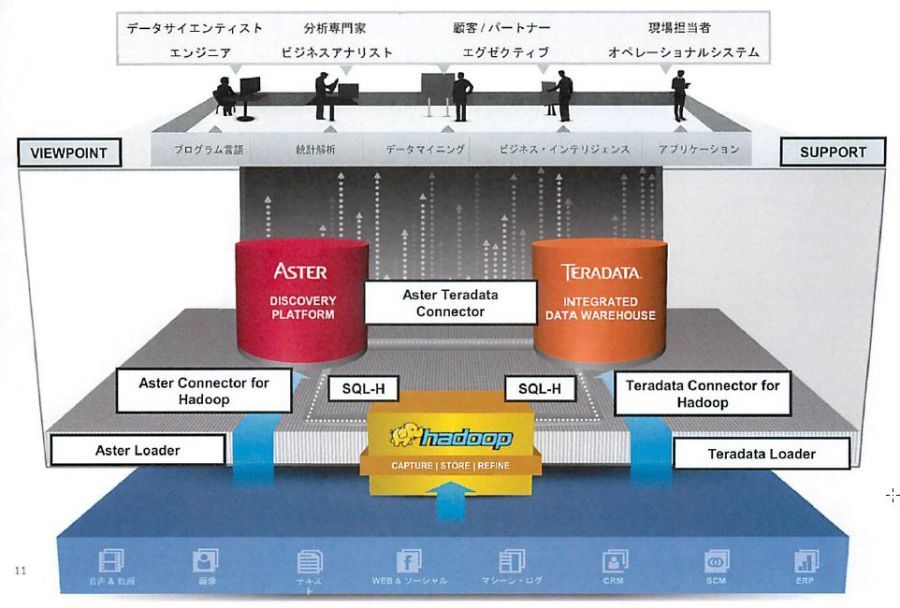
つまりUDAは、同社のDWH製品である「Teradata」、非構造化データをSQL形式で分析するツール「Aster」(テラデータが買収したAster社の製品)、それに非構造データを蓄積・管理するHadoop(提携先のHortworksのディストリビューション)の3つのデータ基盤の間で、基盤の違いを意識せずに分析処理を実行したり、必要なデータを移動したりするための枠組み、あるいは考え方である(図1)。


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
