Box Japanは2026年1月16日、重要データ自動抽出ツール「Box Extract」を提供開始した。生成AI/大規模言語モデル(LLM)を使って、契約書や製品仕様書などの非構造化データ/ファイルから必要な情報を抽出・構造化する。これまで手作業に依存してきた情報の抽出処理を自動化する。
Box Japanの「Box Extract」(画面1)は、クラウドストレージ/文書管理サービスの「Box」において、契約書や報告書などの非構造化データ/ファイルコンテンツから必要な情報を抽出して構造化するツールである。抽出した情報は、メタデータとして非構造化データ/ファイルと共にBoxに保存する。
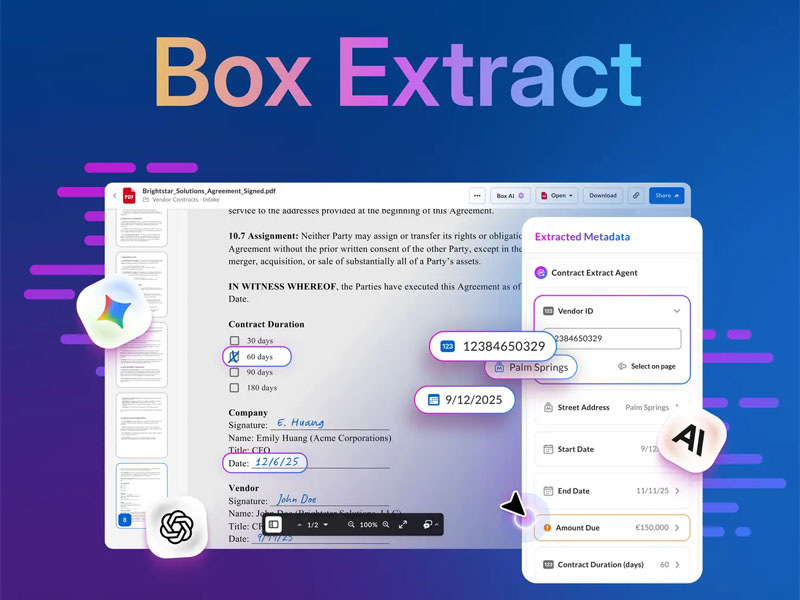 画面1:非構造化ファイルから必要な情報を自動で抽出するツール「Box Extract」の画面例(出典:Box Japan)
画面1:非構造化ファイルから必要な情報を自動で抽出するツール「Box Extract」の画面例(出典:Box Japan)拡大画像表示
OCR(光学文字認識)は、単にテキストを抽出することに重点を置いているが、Box Extractは、「Gemini 3」「Claude Opus 4.5」「GPT 5.2」などの生成AI/大規模言語モデル(LLM)を使い、段落、表、図表などの構成要素に分解したうえで重要な情報を抽出する。
「組織のナレッジは、蓄積した日常業務に関わる非構造化データ/ファイルの中に存在する。これまで非構造化データから知見を引き出す試みは手作業で行われており、コストが高くつき拡張性に欠けていた。Box Extractは、こうした課題を解決する」(Box Japan)
Box Extractでは、「標準」と「強化」の2種類の抽出エージェントを用意している。標準版は、単純なデータ取得を効率化する。強化版では、マルチモーダルの文書構造に基づいた専門的な処理を実施し、より深い推論を適用して大規模・複雑・可変性の高いデータ/ファイルから必要な情報を抽出する。また、業務要件に合った情報を抽出するカスタムエージェントも作成することができる。
先行事例として、金融サービス会社の米Valmark Financial Groupと米テキサス州自動車局を挙げている。ValmarkはBox Extractを使って、口座申込書、保険商品説明書、手数料明細書などから情報を抽出している。テキサス州自動車局は、州民サービスの提供にあたって、フォームや記録から重要な情報を自動で抽出し、手作業によるレビューを減らしている。


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
