過去から現代に至る情報量の増大過程において、現時点においてすでに「情報の爆発」が起こっている。「情報の爆発」によっていったい何が起ころうとしているのだろうか。おそらくこの現象が、エンタープライズ2.0のすべての根元だと考えられる。通常の手段では管理できないほどの情報が溢れ、そこから有意な情報を見つけ出す、あるいは発見するために検索、ここでは特にエンタープライズサーチが有効な手段であることを紹介する。
技術的背景:検索機能に特化したアルゴリズムとパフォーマンス
エンタープライズ2.0は、サーチプラットフォームで非常に戦略的に統合しており、それによって、企業とシステムの全体を管理するというケースが登場し始めている。その1つの基本的な背景というのは、次の1枚の図が表現している。
これはサーチから少し外れるが、RDBをベースとした30種類くらいのSQLのベンチマークである。横軸がレスポンスタイム、縦軸が頻度となる。ブルーが通常のRDBのレスポンスタイムで、オプティマイズされると4割くらいのものは16分の1秒以内に収まっている。横軸で見ると分かりやすいが、複雑なクエリが入ってしまうと、20秒、30秒になってしまう。これがRDBの特徴である。
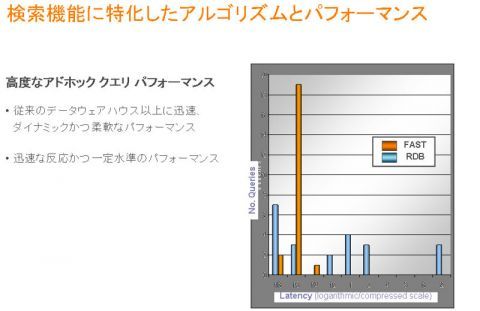
図 検索機能に特化したアルゴリズムとパフォーマンス
それに対して、この事例ではFASTのオレンジの部分の100パーセントが4分の1秒以内に収まっている。これはどういうことがというと、RDBのような更新系のシステムでは、ロックメカニズムを避けて通れない。データのインテグリティを保たなければならないため、ありとあらゆるところでロックをかけなくてはならない。ある意味、SQL DBの制約は、この点にあるといえる。
検索というのは、基本的にはリードーオンリーである。つまりロックというボトルネックが外れて、オプティマイズされた結果、サーチによるハイパー パフォーマンスメカニズムを生むことができる。コロンブスの卵ではないが、更新系と参照系を明確に分けるというのは、非常に有利な事例となる。
日本では、リクルートが非常に大きな現業部門でリードオンリー系をサーチに変えたことによってRDBのワークロードが40%程度減少し、パフォーマンスが2倍にもなったという事例がある。
すでにこうした事例が出始めている時代になっている。そして次の段階として、メリルリンチなどの大手の金融機関は、基幹系システムを含めて、サーチプラットフォームで、システムの再構築を始めているのだ。
サーチ:基本的構成要素
エンタープライズ2.0、ウェブ2.0といったときに考える検索は、コンポーネント的に考えると、3つぐらいしかない。情報の取り込み、情報を選択、そして利用頻度だ、リアルタイムで情報を取り込み、その場で登録するという極端な例から、マンスリーな情報を取り込んでいくものもある。ニュース系だったら、検索対象をどこまでとってくるのかと、情報の取り込み方もさまざまだ。コンテンツ リファイメント パイプラインと書かれた、図の左側の「検索対象」からまとめて情報を得る。その構造化データと自然言語的なデータ、マルチメディア的なデータを共通の軸でどのように統合していくのか、ここが重要なポイントになっている(後述)。
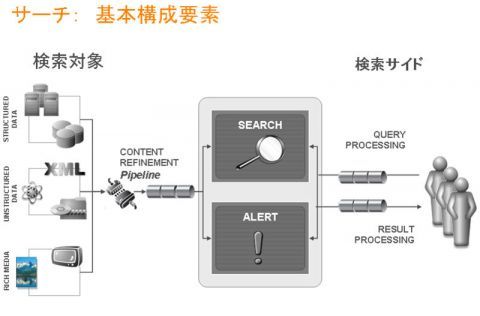
図 検索の基本構成要素
複数の企業をM&Aした結果、3つも4つも分散しているCRMのシステムを統合するというのも、実はここのコンテンツ リファインメントを含めて統合していく。図の右側における検索サイドは、基本的にはクエリープロセッシング(質問を投げかける側)である。集めた検索をどのように見るのかというのが、重要なテーマとなる。
質問する側は当然、個人によっても部門によっても異なったものとなる。パーソナライゼーションとは、過去にこういう事例があったから、「この人はこういうことを知りたいだろう」というところまで絞り込んでいくことだ。具体例でいうと、カタカナで「オート」と書くと、人によっては半角だったり、全角だったり、それぞれだが、最低限「オート」とやれば、「車」にまつわるすべてのことが出てくる。あるいは「自動車」というキーワードでも情報を引き出すことができる。もう1つ「付加価値」をつけると、ファイナンシャルタイムス系などがそうだが、「オート」と入れた途端にホンダからGM、クライスラー、自動車業界の情報がまとめて引っ張ってくることができる。クエリープロセッシングのところも、非常に付加価値が出てくる商品なのだ。
最終的には右下にあるリザルトプロセッシングで、検索結果を顧客に渡すときに、企業や個人にとって大事なものから優先的に表示する。こういったロジックを明確にして、情報を提供する側が明確な方針を持たなければならない。決してブラックボックス的なものではなく、企業の基本思想を反映したものが、リザルトプロセッシングとして重要になる。eコマースの現場では、この検索結果1つで、利益率が違ってくることにもなる。
構造化・非構造化データの統合:パイプライン
構造化・非構造化という課題、つまりどうやって数値データなのか、ワープロのデータなのかブログのデータであるのかを見分け、統合化を図るのかということは、サーチの重要な課題だ。この事例では、データを取り込んだ段階でいろいろなランゲージディテクション(Language Detection)を行っている。
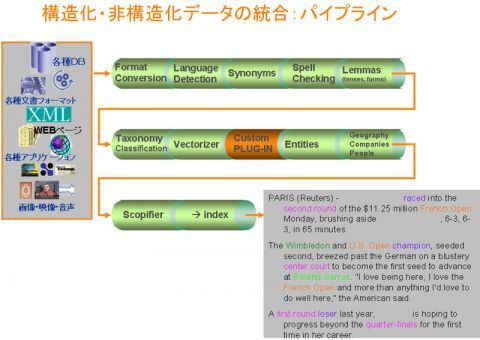
図 構造化・非構造化データの統合
先進的なユーザーでは、日本語の検索と英語の検索を、取り込んだ段階で翻訳して一緒にしてしまう。ランゲージディテクションの一番の本質的なものが、右下にある自然言語である。パリのロイター発の事例なのだが、文章の中でオレンジやピンクになっている文字がいわゆるエンティティ ディストラクション、5W1Hの中のWの部分を意味しており、WhoとかWhenのことである。「いつ、どこで、誰が、何をした」的なものが、人名なのか、地名なのか、製品名なのか、金額なのか、ここの段階で分解して、抽出している。抽出したデータが人名だと分かった段階で、顧客ファイルとリンクして、統合したものを出力する。これも辞書やモルフォロジー(Morphology)を使ったやり方などいろいろなアルゴリズムがあるが、企業独自にアルゴリズムをカスタマイズして使う場合もある。
最終的には、顧客がコールセンターで話している声をテキストに落として、顧客名、製品名、クレーム内容などを1つのクラスターという形で統合し、これを基に検索しているという事例もある。
- 「2.0というより√2.0」─エンタープライズ2.0の取材を通じて感じたこと(2007/12/14)
- エンタープライズ 2.0の先進企業のシステム事例─カシオの場合(2007/10/23)
- エンタープライズ2.0企業導入の課題はどこにある? 活用に向けて徹底議論(2007/10/04)
- 住友電工における企業内システムの変革とエンタープライズ2.0(2007/09/16)
- ビジネスとWeb 2.0─企業革新をもたらす先進的Web活用と事例紹介(2007/09/16)
エンタープライズ2.0 / Web 2.0 / エンタープライズ検索 / 楽天 / Fast Search&Transfer


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
