ビッグデータやIoT(モノのインターネット)といったキーワードが象徴するように、競争力を強化すべく企業が業務オペレーションやアナリティクスの対象として価値を生み出す可能性のあるデータはますます多様化し、爆発的な勢いで増大している。そうした状況下でストレージ・インフラに求められるのが、「膨大なデータの効率的な保管」と「データ分析性能の高速化」だ。ここにIBMはどのような解を提示するのか。2015年11月26日に都内で開催されたセミナー「IoT/ビッグデータ時代のストレージ選択」(主催:インプレス)において、日本アイ・ビー・エムが来場者に訴求した最新ソリューションの内容を紹介する。
これまでにないビジネス価値を創造する
コグニティブ・システム
昨今、社会のいたるところで日々膨大な量のデジタルデータが生み出され、さらに猛烈な勢いで増え続けている。その一方で、これらのデータのうちの80%は有効に活用されないまま保管または廃棄されているという調査結果がある。テキストデータや画像/動画データ、センサー&デバイスデータなど、従来の分析基盤では扱いづらい非構造化データが膨大なデジタルデータの大半を占めているのがその理由である。裏を返せば、こうしたいわゆる非構造化データをもっと効率的に活用できるようになれば、ビジネスに新たな価値を提供できると考えられる。
 日本アイ・ビー・エム株式会社 IBMシステムズハードウェア事業本部 ストレージセールス事業部 ビジネス開発 シニアITスペシャリスト 佐野鉄郎氏
日本アイ・ビー・エム株式会社 IBMシステムズハードウェア事業本部 ストレージセールス事業部 ビジネス開発 シニアITスペシャリスト 佐野鉄郎氏この課題に向けてIBMが注力しているのが、「IBM Watson」に代表されるコグニティブ・システムである。「データ分析の習熟度を従来の現状認識や事前予測といったレベルから、学習と知識の蓄積へと飛躍させていきます」と、この技術の意義を語る日本アイ・ビー・エムのシニアITスペシャリストである佐野鉄郎氏は、従来の分析技術とコグニティブ・システムの具体的な違いを次のように説明した。
コグニティブ・システムは、自然言語による質問が可能で、システム自身が仮説を立てて答えを探るとともに、導き出した結果に対して複数の選択肢と根拠を提示する。さらに、システムが繰り返し学習を重ねることで、精度をどんどん高めていく。これによって分析技術は一部の専門家のためのものではなく、誰もが使える良きアドバイザーとなる。
そして佐野氏は、こうしたコグニティブ・システムを支えるインフラ・テクノロジーとして、「膨大な非構造化データの効率的な保管」と「データ処理性能の高速化」という2つのアプローチに言及した。
膨大な非構造化データをいかに効率的に保管・運用するか
まず「膨大な非構造化データの効率的な保管」において重要な鍵を握るのが、ストレージをソフトウェアによって定義・制御する「SDS(Software Defined Storage)」の仕組みである。ただ、一言でSDSといっても、そのとらえ方はベンダーによって様々だ。データアクセスのみを対象としたストレージ仮想化の仕組みをSDSと称しているケースも見受けられる。これに対してIBMでは、「運用監視や自動化、バックアップなどのコントロール機能を含めたトータルなソリューションとして、SDSのポートフォリオを用意しています」と佐野氏は言う。これが「IBM Spectrum Storage」の全体像である。
このポートフォリオの中から今回紹介したのが、「Spectrum Scale」という拡張性を高めたファイルアクセスのソリューションだ。「最大16,384ノードまで拡張できるスケールアウト型ストレージとして、最大2の99乗バイトの巨大な単一のファイルシステムを構成することができます」と佐野氏はその先進性を強調する。2の50乗がペタ、2の60乗がエクサであることから、その他のファイルシステムと比較して、Spectrum Scaleがいかに圧倒的な拡張性を持っているのか推測できるだろう。
Spectrum ScaleはNFS、SMB、Hadoop MapReduceなど多様なプロトコルに対応するほか、OpenStack Object Storage(Swift)やAmazon S3などにも対応しオブジェクト・ストレージとしての活用も可能だ。まさに、爆発的な勢いで増え続ける非構造化データに“打ってつけ”の保管庫となるのである。
もっとも、巨大なデータを必ずしも地理的に1カ所に集めて保管できるとは限らない。むしろ本番サイトのほか工場や支社などのリモートサイト、パブリッククラウドなど、複数サイト間で分散して保管・運用するケースのほうが多いのではないだろうか。
「Spectrum Scaleは、こうした遠隔地のデータ利用も効率化します」と佐野氏。これを実現するのが「AFM(Active File Management)」と呼ばれる機能であり、WANキャッシングにより各サイトでのデータアクセスを高速化するほか、ファイル同期をバックグラウンドで自動的に実施する。
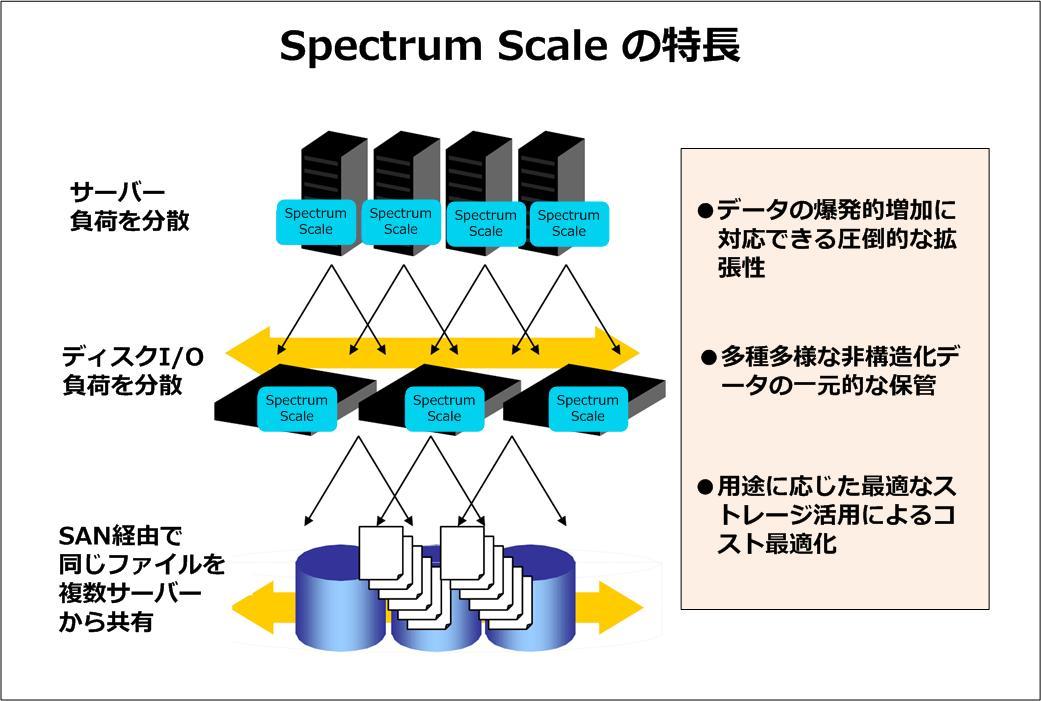 図1 IBM Spectrum Scale の特長
図1 IBM Spectrum Scale の特長拡大画像表示




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
