レトリバは2024年3月10日、RAG(検索拡張生成)システムの検索精度を高めるEmbedding(テキスト埋め込み)モデル「RetrievaEmbedding - 01 AMBER(Adaptive Multitask Bilingual Embedding Representation)」を公開した。RAGで検索するテキストを数値化(ベクトル化)するモデルで、日本語検索用途に最適化している。
レトリバの「RetrievaEmbedding - 01 AMBER(Adaptive Multitask Bilingual Embedding Representation)」は、RAG(検索拡張生成)システムの検索精度を高めるEmbedding(テキスト埋め込み)モデルである。RAGで検索するナレッジを数値化(ベクトル化)するモデルで、日本語検索用途に最適化している。求める情報を正確・迅速に得られるようになるとしている(図1)。
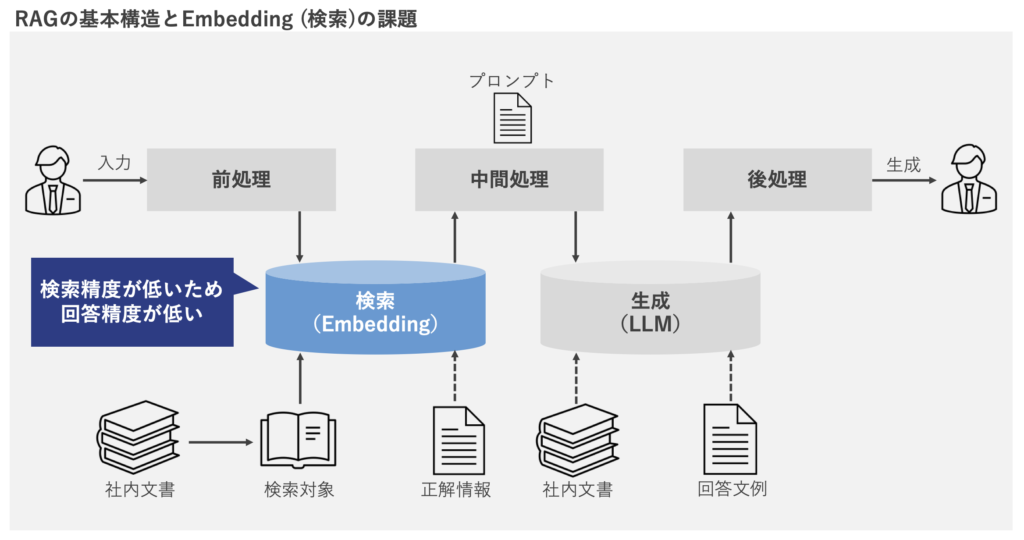 図1:RAGシステムにおけるEmbeddingモデルの役割(出典:レトリバ)
図1:RAGシステムにおけるEmbeddingモデルの役割(出典:レトリバ)拡大画像表示
商用利用可能なライセンスの下で、315Mパラメータの「AMBER-large」と132Mパラメータの「AMBER-base」の2種類のモデルをHugging Face Hubで公開している。
特徴として、500M以下パラメータの小規模なモデルでありながら、日本語検索精度が高いことを謳う。レトリバが実施したAMBERの日本語検索精度のベンチマークテストで、公開中の他の小規模な日本語/多言語埋め込みモデルに比べて高いスコアになっている(図2)。日本語以外にも、日本語と英語が混在している文書に対しても高い検索性能が得られるという。
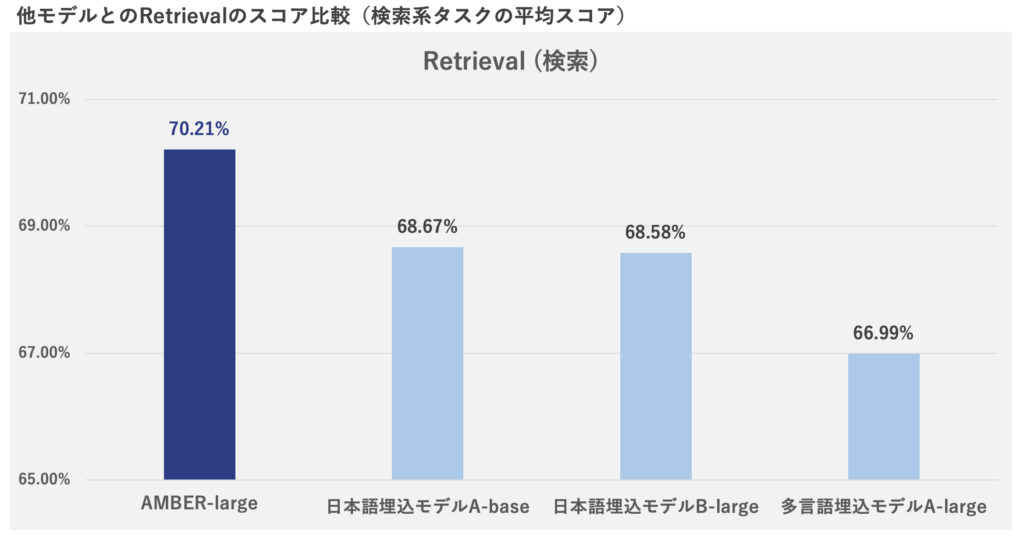 図2:AMBERと他のモデルの日本語検索性能比較(出典:レトリバ)
図2:AMBERと他のモデルの日本語検索性能比較(出典:レトリバ)拡大画像表示
「日本企業は生成AIの活用が欧米と比べて遅れている。なかでもRAGは期待の高さの割に十分に活用が進んでいない。要因の1つとして、RAGの重要な要素であるEmbeddingモデル技術に関し、日本語のモデルが英語に比べて整備されておらず、企業の多くは検索精度が不十分なEmbeddingモデルを利用している」(レトリバ)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
