データ群から「ビジネスを牽引する知見」を引き出すには、具体的にどのような知識体系やスキルが必要になるのだろうか。本パートでは、データサイエンティストの典型的な実務フローに照らしながら、「分析」「ITスキル」「ビジネス知識」の3つの面に踏み込んでみる。
ビッグデータ時代の到来により、データ分析のあり方は姿を変えつつある。基幹システムのデータベースだけでなく、Webサイトやソーシャルメディア、スマートフォン、公開データなど、さまざまなデータソースから得た情報を使って、顧客ごとに趣味嗜好にあった商品を提案したり、いち早くクレームに対応したり、将来の売上の変化を予測したりできるようになった。
ただし、“果実”を得るのはそう簡単ではない。新しいデータから価値を引き出すためには、新しい道具立てが求められる。Part1では、その体系を“データサイエンス”と呼んだ。以下では、それらをもう少し、具体的に見ていくことにしよう。
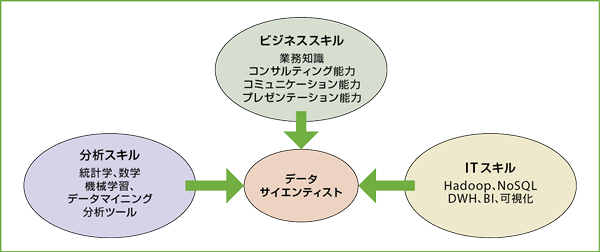
〔分析スキル〕ビッグデータの活用でも使用する手法は変わらない
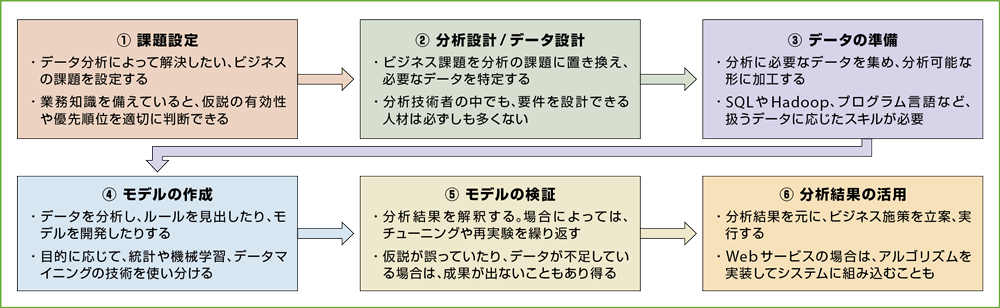
ビッグデータ活用といえど、分析の手順は基本的に変わらない(図3-2)。大量の非構造化データをそのまま分析するのではなく、一定数のサンプルを抽出、分析ソフトウェアに取り込み、試行錯誤を繰り返して、データに潜むパターンや規則性を表す「モデル」を構築する。その後、他のサンプルデータにモデルを適用し、精度を検証するのが基本的なフローである。
データを分析する際は、統計解析やデータマイニング、機械学習といった手法を目的に合わせて使い分ける(図3-3)。手法そのものは、データアナリスト、データマイナー、モデラーと呼ばれる人々も使用してきた。必ずしも新しいものではない。
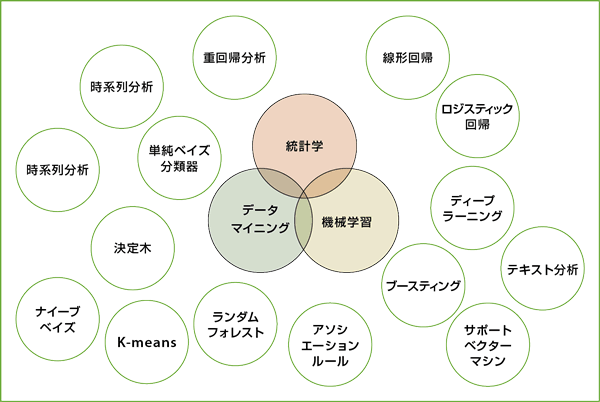
図に示したのはほんの一例。実際には無数の手法があるが、性質に応じて、いくつかのグループに分類できる。具体的には、①データ同士の関係性を調べる、②データを似たもの同士のグループに分ける、③データをカテゴリに分類する、④頻出するデータのパターンを探すといったものが代表的だ。
なお、データサイエンスの要素として、数学や統計学が挙げられることもある。これは、分析手法の多くが、こうした学問をベースとしているためだ。必ずしも高度な知識がなくても、分析ソフトウェアは使うことはできる。ただし、データを適切に抽出したり、分析結果を検証するためには、統計学の知識が欠かせない。「統計学や数学の知識があると、どの手法を使うとパフォーマンスや精度が上がるかといった判断もできるようになる」(リクルートの西郷彰シニアアナリスト)。
予測精度の向上に必須の機械学習
従来のデータ分析と比べて、異なる部分があるとすれば、機械学習が重要度を増している点だろう。機械学習は、コンピュータに自動的にモデルを構築させ、データを認識したり、分類したりできるようにする技術。
例えば、スパムメールのフィルタリングにも利用されている。サンプルデータを使って、スパムメールの規則性を表すモデルを自動的に構築。受信したメールがスパムかどうかを判別する。最近では、商品のレコメンデーションや、ユーザーの行動分析、検索エンジンでのクエリの推測をはじめ、さまざまな用途に使用される。
機械学習の精度は学習するデータ量に比例するが、データ量が増えるほど計算量も飛躍的に増す。精度を向上させるためには、大量のメモリーを用意する必要があるため、利用のハードルが高かった。分散処理フレームワークHadoopの登場などによって、比較的容易に使えるようになったため、データ分析で用いやすくなった(後述)。
「統計的な手法でも、ある程度なら予測はできるが、精度やスピードといったパフォーマンスを追求するなら、機械学習は不可欠だ」(アイアナリシスの倉橋一成代表)。
会員登録(無料)が必要です


- 1
- 2
- 3
- 4
- 次へ >
データサイエンス / データサイエンティスト / iAnalysis / ブレインパッド


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
